部落格
生成式 AI · 企業 AI · 即時 AI
- 球員大腦揭秘:現代足球致勝關鍵是「心流狀態」?
探討在現代高強度競技中,頂尖球隊如何透過神經科學與大腦訓練,幫助球員進入「心流狀態」,並將這些科學概念轉化為日常訓練指南。
- Anthropic 推出 Claude Tag:讓 Claude 成為團隊的常駐 AI 隊友
Anthropic 發布了專為團隊協作打造的 Claude Tag。透過在 Slack 中標註 @Claude,讓 AI 成為能主動參與討論、執行非同步任務並不斷學習的虛擬隊友。本文將詳細介紹其核心功能、使用方式、目標受眾及計費模式。
- 走入 Agent 時代:拆解 Cursor / Claude Code / Codex 的四大核心基石
深度解析現代 AI 編輯器的四大 Harness 機制——Skills、Subagents、Commands 與 Hooks。釐清各平台實際設定格式、觸發時機與協作關係,從「提示詞工程」進化到「AI 工作流架構師」。
- Google 發布 Agentic Resource Discovery 規範:AI Agent 時代的「能力黃頁」
深度解讀 Google 於 2026 年 6 月發布的開放規範 Agentic Resource Discovery(ARD)。這套規範旨在標準化 AI Agent 在分散式系統中尋找、驗證、並連接工具、技能與其他 Agent 的方式,解決多 Agent 協作的核心痛點:「我要怎麼找到可信的合作夥伴?」
- OpenAI 最新研究:強化學習 (RL) 如何讓 AI 系統更加對齊與具備韌性
深度解讀 OpenAI 關於強化學習 (RL) 與 AI 對齊的最新研究。探討模型如何透過專注於「有益特徵」的訓練,在超過 40 項未曾見過的對齊基準測試中展現廣泛的泛化能力,並在惡意微調與對抗性提示下展現強大的持久性與韌性。
- Anthropic 最新研究:代理寫程式 (Agentic Coding) 的現狀與領域專業的持續價值
Anthropic 發布對 40 萬次 Claude Code 互動數據的隱私保護分析。研究揭示了 AI 程式碼代理的真實分工:人類決定「做什麼」,AI 決定「怎麼做」。更重要的是,成功並非取決於「寫程式能力」,而是「領域專業知識」。這對未來的知識工作有著深遠的啟發。
- OpenAI 發表「部署模擬」(Deployment Simulation):解決評估覺醒,更真實地在發布前預測 LLM 安全性
深度解讀 OpenAI 提出的最新大語言模型安全性評估方法「部署模擬」(Deployment Simulation)。剖析如何透過重播歷史真實用戶對話前綴,擺脫傳統紅隊測試中模型的「評估覺醒」與應試行為,對 GPT-5 系列模型實現高精度的風險預測,並使用簡潔的流程圖與預估圖表進行完整說明。
- PixelRAG:Web 截圖擊敗文本檢索!百萬級像素原生 RAG 系統深度剖析
解讀 UC Berkeley 等機構提出的 PixelRAG 系統,剖析其定制 Chromium 渲染、GPU 加速預處理、LoRA 雙塔視覺嵌入與 Text Warmup 訓練配方,並教你如何將其實現為 Claude Code 的網頁視覺閱讀技能。
- Google Cloud 推出 Open Knowledge Format (OKF):讓 AI Agent 讀懂企業知識的開放標準
深度解讀 Google Cloud 提出的 Open Knowledge Format (OKF) 規範。剖析如何將傳統 LLM-wiki 模式標準化,透過簡潔的 Markdown、YAML 前置屬性與互聯結構,打破企業知識孤島,為 AI Agent 提供可攜式、高互操作性的知識底座。
- Zellij 終極極客修煉手冊:多線程終端機的快捷鍵、複製貼上與滑鼠操作
把 Zellij 最常用的核心快捷鍵、複製貼上、背景常駐與滑鼠操作濃縮成一份可隨時查閱的修煉手冊。涵蓋 Pane / Tab / Scroll / Session 四大模式、三大必殺技,以及 config.kdl 與 alias 的一次性優化設定。
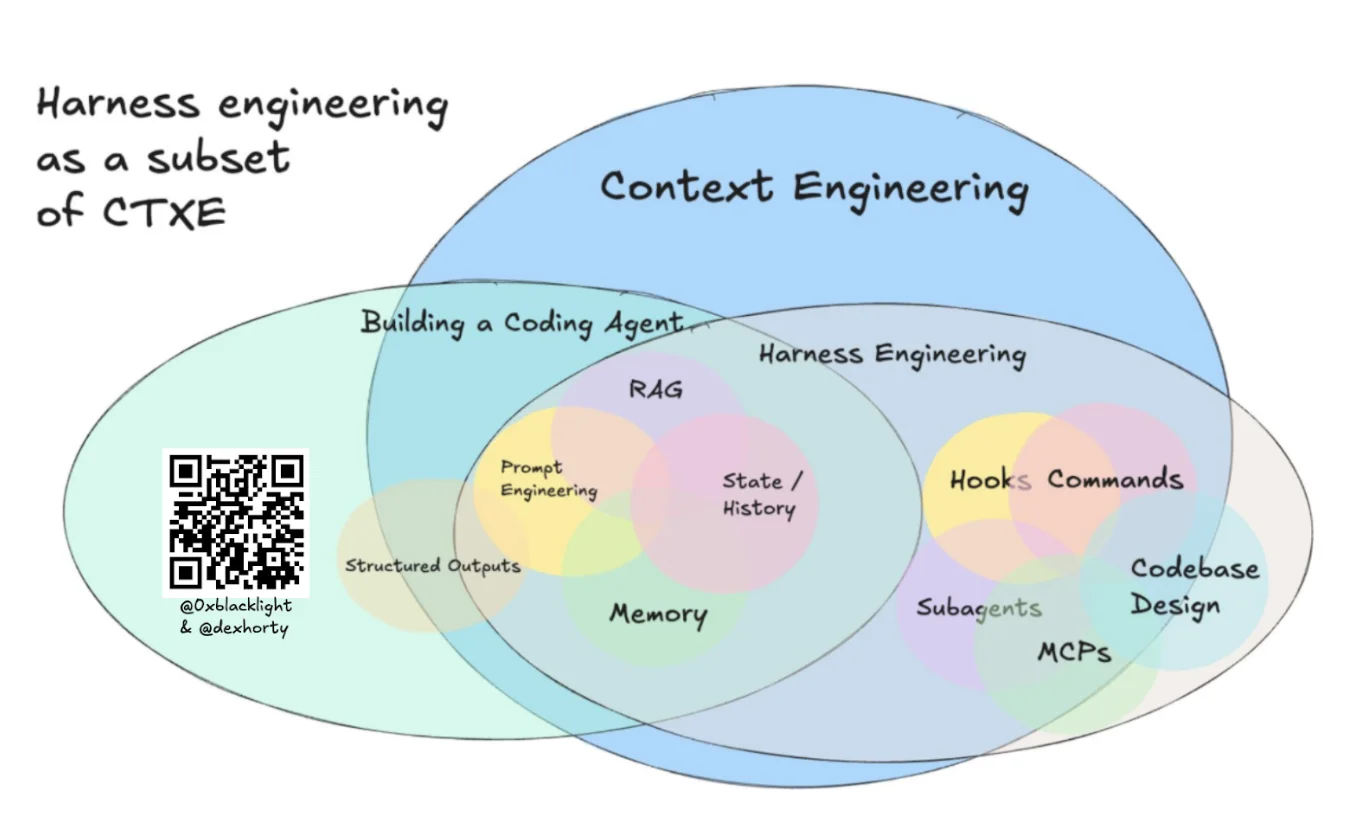
- Harness Engineering 導覽
本站 Harness Engineering 專區的起點:概念、全系列文章索引,以及依角色與情境的閱讀路徑。
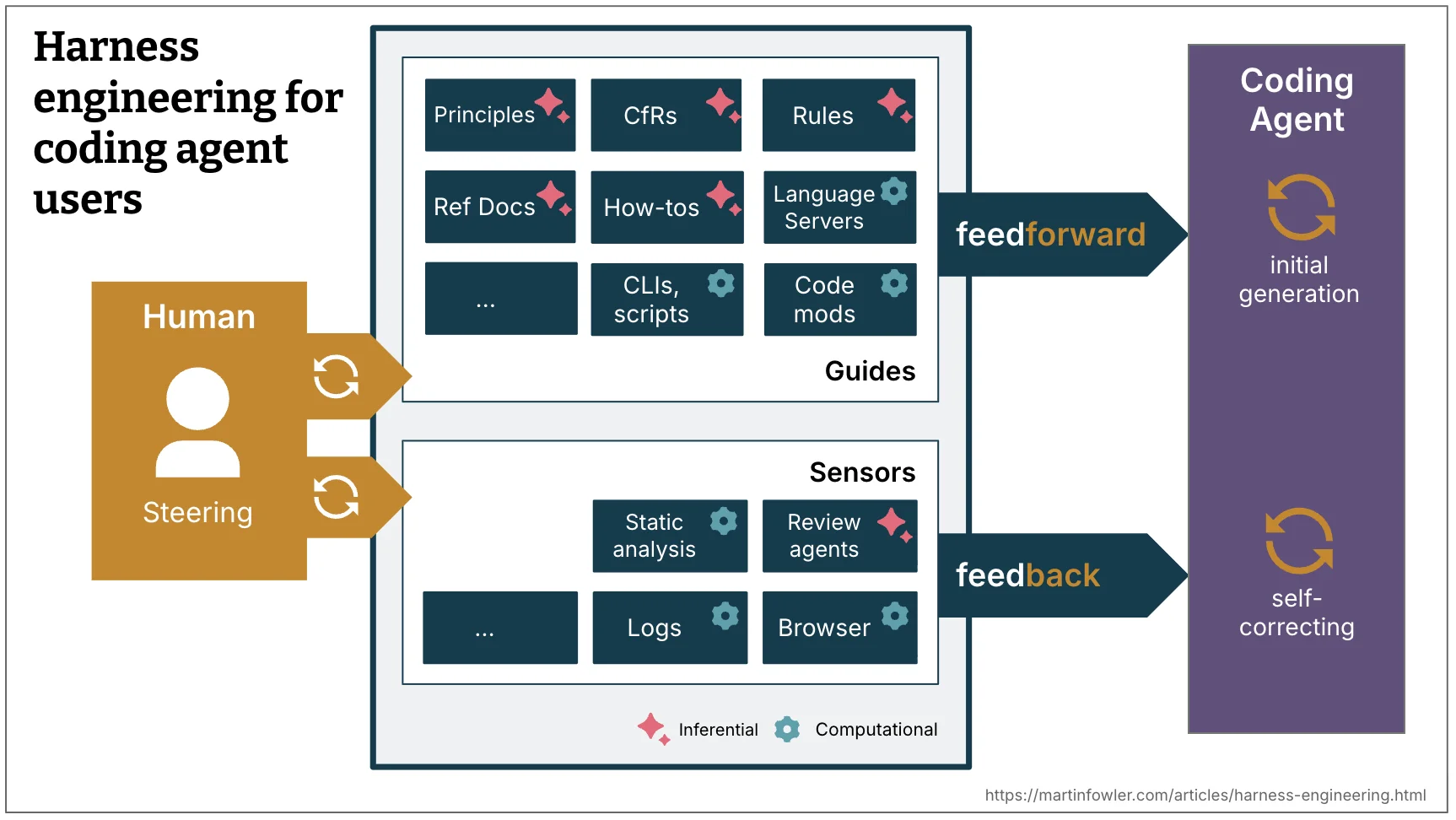
- Martin Fowler 談 Harness:如何用控制迴路建立對 Coding Agent 的信任
深讀 Thoughtworks 評析文:guides/sensors、computational/inferential、三類 regulation 與行為 harness 缺口,並對照 OpenAI 實戰與常見 Agent 失敗模式,整理可落地的 Harness 盤點表。
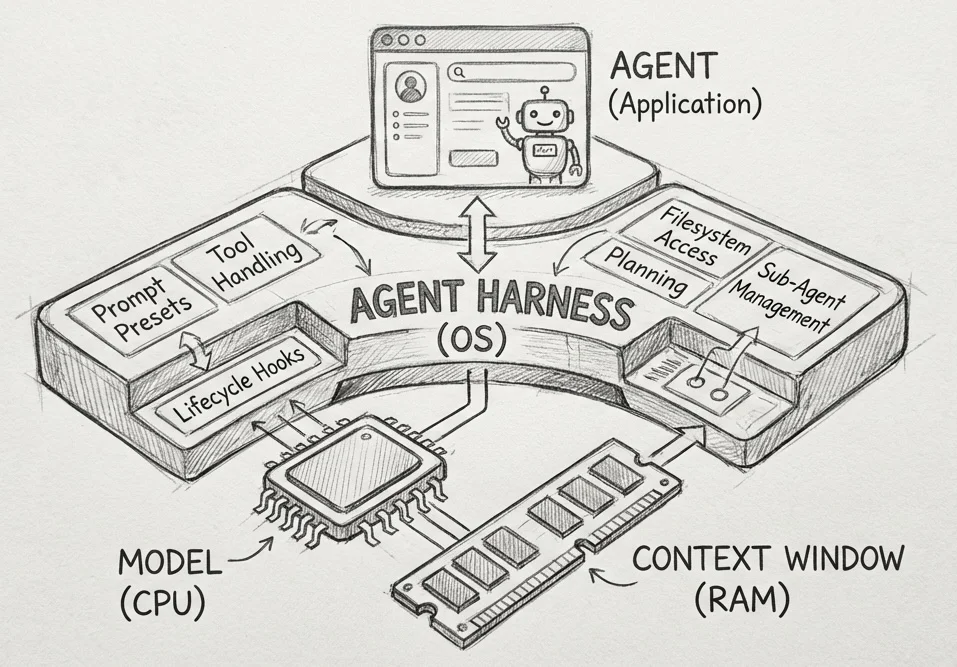
- LangChain 解剖 Agent Harness:從模型能力到可交付的工作引擎
深讀 LangChain 長文:Harness 的正式定義、由期望行為反推的元件鏈(檔案、Bash、沙箱、記憶、Context Rot、Ralph Loop),以及模型–Harness 共訓與 Terminal Bench 的啟示。
- Mitchell Hashimoto 的 AI 採用六階段:從丟掉 Chatbot 到 Harness Engineering
深讀 Hashimoto 親筆歷程:三階段工具採用、重做 commit 練功、離峰與 slam dunk 委派、AGENTS.md 與可驗證工具,以及「總有一個 Agent 在跑」的現狀與限制。
- 16 個平行 Claude 建 C 編譯器:Anthropic 的 Agent Teams 與長程 Harness 實驗
深讀 Nicholas Carlini 實驗文:近 2000 次 session、約兩萬美元 API、十萬行 Rust 編譯器能編 Linux 6.9——鎖任務、測試 Harness、GCC oracle、多角色分工與能力邊界。
- Phil Schmid:2026 年 Agent Harness 為何比模型排行榜更重要
深讀 2026 年 1 月長文:durability、OS 類比、系統評測缺口、Bitter Lesson 下的輕量 Harness,以及 hill climbing 與訓練—推理收斂。
- Parallel.ai 科普:Agent Harness 是模型以外的整條生命週期
深讀 Parallel 長文:從意圖擷取、工具執行、context 編譯到驗證與持久化,釐清 Harness 與 orchestrator、framework 的差異,並對照 Anthropic/LangChain 實例。
- Ignorance.ai Playbook:OpenAI、Stripe、OpenClaw 收斂的 Harness 實踐
深讀 2026 年 2 月橫向整理:工程師工作分裂為「建環境」與「管 Agent」、架構當護欄、工具即回饋、AGENTS.md 當系統紀錄,以及規劃與執行分離。
- HumanLayer:Coding Agent 的 Skill Issue——五類 Harness 設定面實戰
深讀 HumanLayer 長文:失敗常是配置而非模型;釐清 AGENTS.md、MCP、Skills、Sub-agents、Hooks 與 back-pressure,並回應 ETH 研究與 post-training 過擬合爭論。
- 2026 創業新規則:為什麼「建構能力」已不再是核心競爭力
站在 2026 年的創業現場,我們正目睹一場前所未有的範式轉移。在 AI 原生時代,開發成本與時間被極度壓縮,創業的瓶頸不再是「建構能力」,而是「選擇能力」。本文揭示 AI 驅動創業生態中最具顛覆性的核心洞察。
- Agentic RAG:向量搜尋遇上代理推理
整理我在《RAG 2026:當向量搜尋遇上代理推理》報告中的核心觀點:為什麼純向量 RAG 會卡在上下文盲視、為什麼 2026 的方向是向量粗篩加代理精讀,以及企業該如何落地可驗證、可治理的混合架構。
- 長時間 AI 工程的 Harness 設計:生成、評估與驗證鏈
根據 Anthropic《Harness design for long-running application development》整理:用生成-評估分工、外部評測與 QA 合約,提升長任務的可靠性與可控性。
- 長任務代理的 Harness:跨上下文穩定交付
根據 Anthropic《Effective harnesses for long-running agents》整理:用初始化代理(initializer)+漸進式編碼代理(coding)+特徵清單與端到端測試,讓代理能在多個 context window 間持續推進並保持乾淨狀態。
- Harness Engineering:讓 Codex 可觀測可交接
根據 OpenAI 工程文章整理:在程式碼由智慧體生成後,Harness 必須同時提供可讀的知識地圖、強制邊界架構、以及可端到端驗證的回饋迴路。
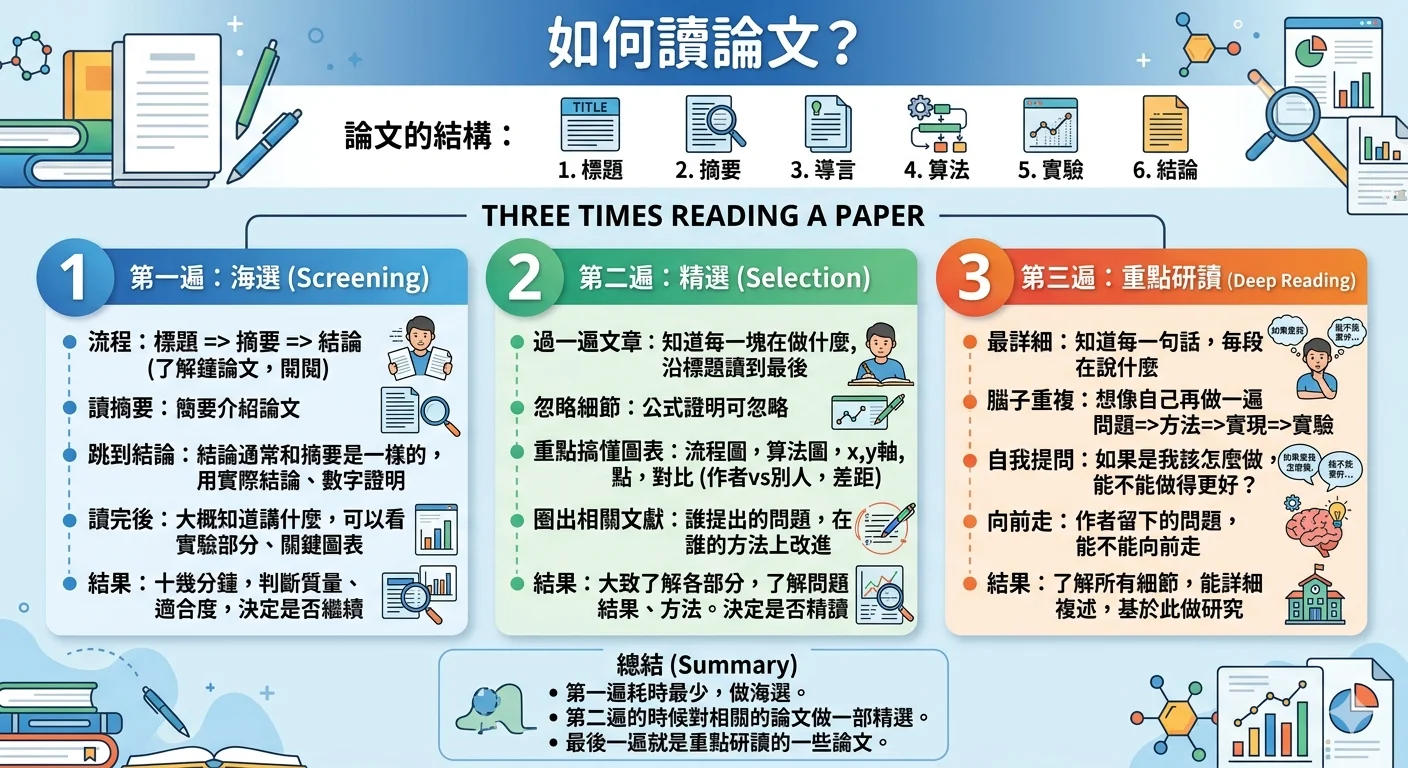
- 高效學術論文閱讀:三遍掃描法
把「三遍讀論文法」落地成可執行流程:用 5–10 分鐘做海選、用 1 小時抓住方法與證據、再用「虛擬重做一遍」吃透細節。本文整合 Keshav 的 three-pass 與李沐老師的實作要點,附檢查清單與文獻綜述讀法。
- AI 對勞動市場的衝擊:從「理論能力」到「實際使用」的新衡量方式
根據 Anthropic《Labor market impacts of AI: A new measure and early evidence》整理:介紹「觀察到的曝光度」指標,說明哪些職業最暴露在 AI 之下、與就業成長與失業率的關係,以及對政策、企業與個人職涯的啟示。
- 推理模型為何「無法控制自己的思路」——反而是 AI 安全的好消息
OpenAI 最新研究發現,現有前沿推理模型幾乎無法依指令隱藏或改變自身的思維鏈(Chain of Thought),可控性最高僅 15.4%。這個「缺陷」不只不是問題,更是當前 CoT 監控機制值得信賴的關鍵理由。
- 不必苦練畫功!揭秘 LINE 貼圖的「邪修」快速上架指南:不會畫畫也能完成的上架教學
給不會畫畫也想做 LINE 貼圖、快速搞懂上架流程的創作者,從題材選擇、角色設定到工具與實作的一條龍 LINE 貼圖上架教學,走一條不靠高超畫技、專攻「題材 x 流程」的邪修路線。
- 打造有效的 AI Agent:架構模式與實作策略總覽
根據 Anthropic《Building Effective AI Agents》整理:從單一 Agent 到多 Agent 協作、常見架構模式、工作流設計,以及如何依控制需求、問題複雜度與資源選擇合適架構。
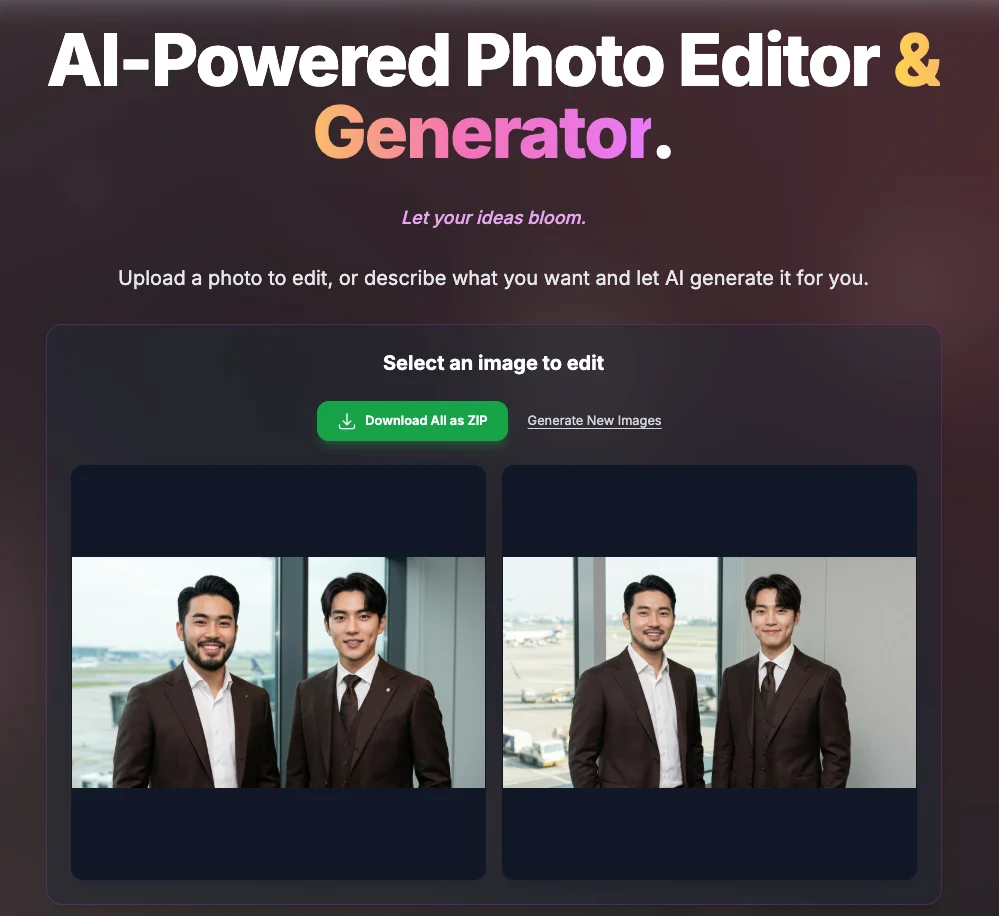
- BloomRender 操作手冊:從文字生圖到證件照、形象照、旅遊照與虛擬試穿
BloomRender 是以 Google Gemini 驅動的 AI 照片工作室。本篇詳述文字生圖、AI 證件照、編輯器微調、形象照、旅遊照與虛擬試穿的完整操作流程與建議學習路徑。
- AI IDE、Code Agent 與 Vibe Coding
從傳統 IDE 到 AI 協作,軟體工程的重心正在從實作能力轉向問題定義與系統設計。我對 Vibe Coding 的理解:在不確定性中建立可控的開發流程。
























正在找 AI 平台或 Agentic AI 夥伴?我協助團隊交付企業級 RAG、多代理與即時 AI 系統。
聯絡