PixelRAG:Web 截圖擊敗文本檢索!百萬級像素原生 RAG 系統深度剖析
擺脫損耗嚴重的 HTML/PDF 解析,讓 LLM 擁有直接「看懂」網頁結構的雙眼
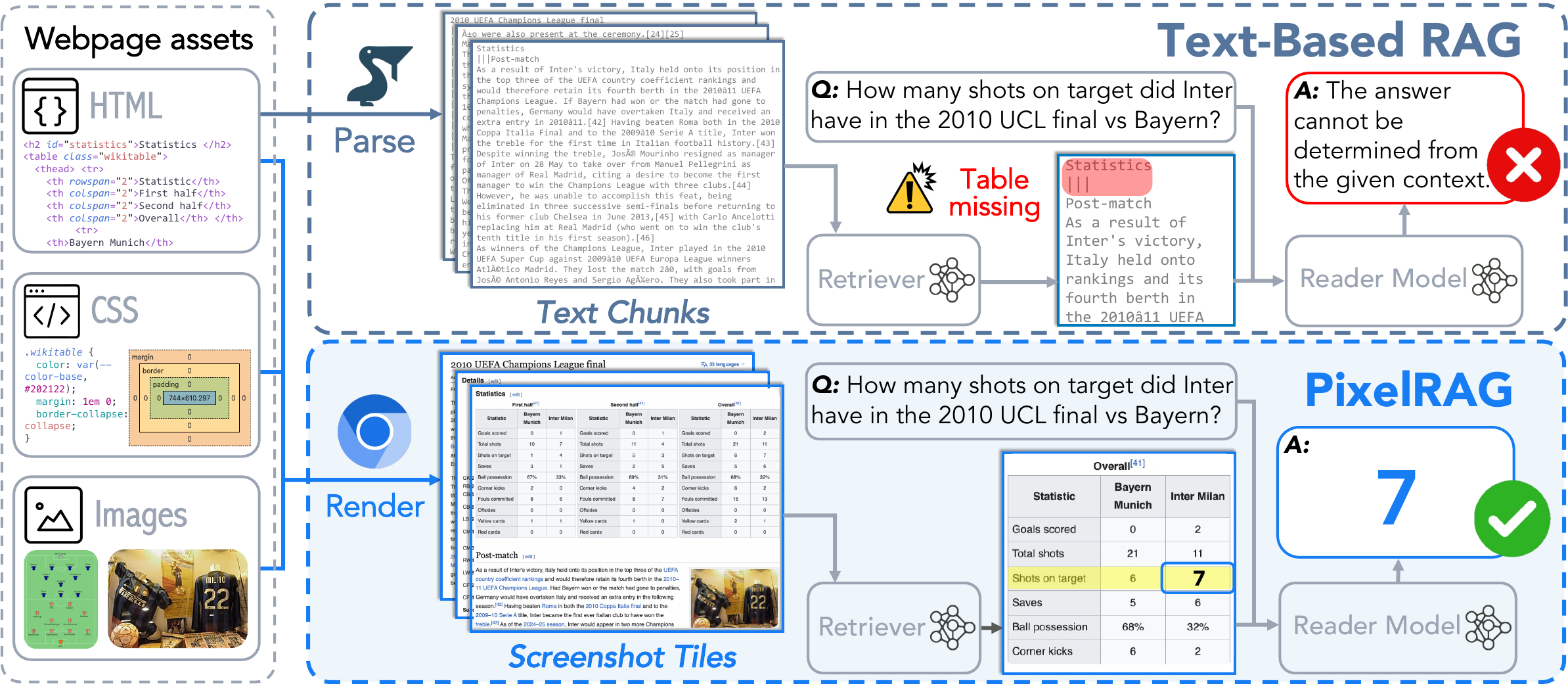
在目前的檢索增強生成(RAG)領域,絕大多數系統都依賴於**「解析-提取-檢索」**的文本化管道:將 PDF、網頁或圖片解析為純文本,分塊(Chunking)後透過文本嵌入模型建立索引,最後交由大語言模型(LLM)進行回答。
然而,這種傳統的文本 RAG 存在著不可避免的**「信息斷崖」**:
- 結構化資訊丟失:複雜的表格、多欄排版、思維導圖和流程圖在轉效為純文本時往往被徹底打亂,失去關聯。
- 多模態內容被拋棄:圖表、統計圖、設計稿等視覺元素無法透過文本表示。
- 解析極其昂貴且容易出錯:為了儘可能保留表格和結構,開發者不得不使用複雜的 PDF 解析器(如 PDFPlumber、Unstructured)或 OCR 工具,極其耗時且效果參差不齊。
由加州大學柏克萊分校(UC Berkeley SkyLab & BAIR & NLP)等機構提出的 PixelRAG 徹底顛覆了這一現狀。它提出了一種**「像素原生(Pixel-Native)」**的視覺檢索與生成框架:直接將文檔渲染為截圖切片,利用微調後的視覺-語言模型(VLM)嵌入模型進行端到端的檢索,再交由多模態大模型(VLM Reader)直接閱讀截圖進行回答。
根據論文,PixelRAG 在傳統的文本 QA 任務上比基於文本的 RAG 準確率提升了約 18.1%,且天然支持富含圖表的複雜網頁和 PDF。
以下依 §1 Pipeline & Architecture → §2 Chromium High-Throughput Rendering → §3 GPU-Accelerated Preprocessing → §4 LoRA Fine-Tuning Recipe → §5 Claude Agent Integration 深入解讀其源碼設計與核心技術創新。
§1 Pipeline:五階段像素原生流水線
PixelRAG 的完整運作流程可以分為以下五個核心步驟:
- 渲染(Render):利用高性能無頭瀏覽器將網頁/PDF 渲染並截圖,對應於 render.py 中的 render_url 入口。
- 切片(Chunk):將超長截圖切割為適合 VLM 輸入的標準固定高度切片,由 chunk.py 中的 chunk_article 實現。
- 嵌入(Embed):透過雙塔視覺嵌入模型生成 dense 稠密向量,由 embed.py 管理。
- 建庫(Index):使用 FAISS 建構向量搜索索引,封裝在 api.py 中。
- 服務與閱讀(Serve & Read):提供 API 檢索服務,透過 search 接口檢索匹配的圖片塊,最後送入多模態大模型進行閱讀與解答。
┌──────────────────┐
│ 網頁 / PDF 源文件 │
└────────┬─────────┘
│
[Render] ▼
[chromium] ──► 瀏覽器高性能渲染截圖 (875x8192)
│
[Chunk] ▼
[chunk_article] ──► 垂直切片為 1024px 高度的小圖塊
│
[Embed] ▼
[_init_direct_gpu] ──► GPU加速預處理 + Qwen3-VL-Embedding
│
[Index] ▼
[api.py] ──► 建構 FAISS IVF 索引庫
│
[Serve] ▼
[search] ──► 接收文本/圖像 Query 檢索 Top-K 圖片塊
│
[Read] ▼
[vLLM / VLM]──► 視覺模型直接讀圖生成答案§2 Chromium 定制高性能渲染(109 tiles/s)
對於大規模視覺 RAG 來說,最大的工程瓶頸在於渲染截圖的吞吐量。傳統的無頭瀏覽器(如 Puppeteer、Playwright)在面對數百萬網頁時,由於跨進程 IPC 通訊、Base64 序列化傳輸、網路等待以及磁碟寫入等開銷,吞吐量通常只有每秒幾張圖。
PixelRAG 團隊透過深入 Chromium 底層進行定制開發,修改補丁詳見 chromium-screenshot-patches.diff,並在 screenshot-throughput-optimization.md 中記錄了他們的優化路線。透過這一系列優化,他們實現了 109 tiles/s 的端到端超高渲染寫入吞吐量(性能提升了 5.5 倍):
| 序號 | 優化手段 | 吞吐量 | 相比基準提升 | 關鍵原理 |
|---|---|---|---|---|
| 0 | 基準線 (Playwright, 輪詢等待 30ms) | 20 t/s | — | Node.js IPC 橋接層開銷 |
| 1 | 直接 CDP websocket 通訊 | 23 t/s | +14% | 繞過 Playwright 封裝 |
| 2 | fonts.ready 事件驅動 | 28 t/s | +22% | 棄用定時輪詢,改為字體/圖片事件觸發 |
| 3 | 定制 rawFilePath 補丁 | 33 t/s | +18% | 繞過 Websocket 的 Base64 編碼傳輸 |
| 4 | 多瀏覽器進程 (48 workers) | 79 t/s | +140% | 充分發揮多核 CPU 性能 |
| 5 | Phased 協調與信號量控制 | 96 t/s | +22% | 減少高併發下的截圖硬件爭搶 |
| 6 | .jpg Chromium 內置編碼 | 109 t/s | +15% | 在 Chrome ThreadPool 內完成 JPEG 壓縮直接落盤 |
2.1 rawFilePath 直接寫盤
傳統的瀏覽器截圖需要透過 Chrome DevTools Protocol (CDP) 將圖片轉換為 Base64 編碼,再透過 Websocket 發送給 Node.js/Python 進程,進行二次解碼和保存。
PixelRAG 在 Chromium 原始碼中擴展了 Page.captureScreenshot 接口,支持傳入 rawFilePath 屬性。Chromium 渲染線程在拿到原始 BGRA 像素數據後,透過其內部的 ThreadPool 異步將其直接寫入掛載在記憶體中的共享記憶體盤(/dev/shm),Python 客戶端只接收「寫入完成」的信號,徹底消除了 Websocket 序列化和數據傳輸的頻寬瓶頸。
2.2 Chromium 內部 ThreadPool 異步 JPEG 編碼
如果直接保存無損 PNG,磁碟寫入量大且後續壓縮慢。PixelRAG 補丁讓 Chromium 檢測 rawFilePath 後綴。如果為 .jpg,則自動調用 Chromium 內部的高性能 JPEG 編碼器,在 Chromium 底層的異步工作線程池中完成壓縮,不僅避免了 Python 端的單線程瓶頸,也大大減少了 E2E 耗時。
2.3 directClip 與輕量化 ForceRedraw
在對超長頁面進行分塊截圖時,傳統的做法是不斷改變 Viewport 並滾動頁面。而 PixelRAG 引入了 directClip,可以直接從當前的 Surface 複製指定矩形區域(CopyFromSurface),而不改變視口或模擬狀態。
為了解決高併發下可能捕獲到 about:blank 或未渲染完成界面的競態問題,它在 CopyFromSurface 之前加了一步輕量化的 ForceRedraw 機制,確保合成器(Compositor)已經提交了最新的幀,保證了 100% 的捕獲正確率。
§3 GPU 加速圖像預處理與分塊
文檔截圖(例如 875×8192 px)通常垂直跨度極長,直接輸入給 VLM 嵌入模型會導致視覺 Token 數量呈指數級上升,不僅耗效顯存,還會使模型關注點分散。
3.1 垂直切片策略(Pre-chunking)
在 chunk.py 的 chunk_article 函數中,PixelRAG 將大截圖垂直切割成 1024px 高度的標準小切片。在切割時,它設計了合併微小尾巴的機制(如果剩餘像素小於 28px 則直接合入前一片,避免產生無法被 VLM 正常切塊的小條帶)。 透過這種分塊策略,視覺 Token 數量減少了近 8 倍,吞吐量和檢索精度得到了極大的提升。
3.2 GPU 級別的預處理加速(60x 加速)
在大規模離線生成向量時,圖像的加載、裁剪、縮放和歸一化(Preprocessing)往往成為致命的 CPU 瓶頸。
在 embed.py 的 _init_direct_gpu 中,PixelRAG 巧妙地將 transformers 的 Processor 預處理操作搬到了 GPU 上進行(即直接在 CUDA 設備上處理張量),使得單批次(Batch Size = 64)的圖像預處理耗時從 CPU 上的 12 秒暴降至 GPU 上的 0.2 秒,從而讓顯存可以始終處於被完全榨乾的高效狀態。
§4 雙塔視覺嵌入 LoRA 微調配方
PixelRAG 使用的視覺檢索模型是基於 Qwen/Qwen3-VL-Embedding-2B 進行了 LoRA 深度微調。為了解決「視覺模型只認圖、不認純文本 Query」以及「極易混淆相似佈局網頁」的問題,團隊設計了一套非常精妙的訓練配方(代碼詳見 train_contrastors.py):
4.1 文本預熱(Text Warmup)
在視覺對比訓練的前 50 步(--text-warmup-steps 50),模型首先只輸入**純文本 Query → 純文本段落(Passage)**交配數據進行訓練。這一階段的目的是防止模型在接觸大量截圖圖像後,喪失對複雜文本 Query 的語言理解與對齊能力。
4.2 強負樣本挖掘(Mined Hard Negatives)
對於 visual 網頁截圖,許多網頁的導航欄、背景、甚至是側邊欄都完全相同,只有正文中的幾個數字或圖表有差異。如果使用簡單的 Batch 內隨機負樣本(In-batch Negatives),模型很容易產生走捷徑心理,只透過頁面框架來判斷相似度。 PixelRAG 在數據準備階段為每個 Query 挖掘了 2 個視覺極其相似但實際不相關的 Hard Negatives。在對比學習損失計算時,強迫模型去關注圖像局部的文字細節(例如表格內的具體數值),從而使 QA 評分從 0.715 提升至 0.785。
4.3 GradCache 梯度快取優化
對比學習需要儘可能大的 Batch Size 才能發揮最佳效果,但在訓練 Vision 這樣動輒包含幾千個 Token 的模型時,顯存極易 OOM。 train_contrastors.py 集成了 GradCache 技術。它將一個大 Batch(如 64)拆分成多個小 chunk(如 4)依次進行前向傳播並快取激活值,最後統一進行後向傳播和梯度更新。這使得訓練在有限的單張 H100 顯存上也可以使用龐大的對比 Batch 進行,且數學上完全等價。
§5 AI Agent 的雙眼:Claude Code pixelbrowse 插件
除了作為一個可以私有化部署的大規模視覺 RAG 平台之外,PixelRAG 還能以輕量級插件的形式服務於 AI 終端。在 SKILL.md 中,PixelRAG 提供了適配 Claude Code 的 pixelbrowse 技能插件。
當 Agent 去抓取一個現代 SPA(單頁應用,如 React/Vue 編寫的網站)時,經常會遇到以下尷尬:
- 抓回來的 HTML 是一堆亂七八糟的 JS Bundle
<script>標籤,沒有任何正文。 - 大量的 CSS 類名和 DOM 嵌套極度消耗 Token 上下文。
- 複雜的統計圖表在 DOM 樹中只是一個
<canvas>標籤,Agent 根本看不見數據。
有了 pixelbrowse 技能,Claude 可以直接調用本地的 pixelshot 命令進行截圖讀圖:
pixelshot https://news.ycombinator.com --output /tmp/pixelbrowse --tile-height 1568 --wait-network-idle然後直接用 Vision 接口去閱讀 /tmp/pixelbrowse/xxx.png.tiles/tile_0000.jpg。
💡 Agent 讀圖核心訣竅
--tile-height 1568的奧秘:Claude 3.5 Sonnet 等多模態模型的視覺限制是:當圖像單邊超過 1568px 時,模型內部會自動將其進行等比例降採樣(Downscale)。如果直接截 8192px 的超長圖,降採樣後文字會變得模糊成馬賽克,完全無法識別。所以這裡強制將切片限制在 1568px 高度,保證每一像素的文字都絕對清晰。--wait-network-idle解決 SPA 空白問題:由於大部分現代網頁是客戶端異步渲染,如果瀏覽器只等DOMContentLoaded事件就截圖,可能截出來一幅骨架屏。該參數會讓瀏覽器多等待 500ms 的網路空閒期,確保動態圖表和 JS 數據全部加載呈現完畢。
§6 總結
PixelRAG 從工程優化(定制 Chromium 渲染底座,GPU 預處理加速)到演算法設計(雙塔微調、文本預熱、GradCache),為多模態時代的 RAG 建設提供了一套非常成熟的生產級解決方案。它讓我們意識到:有時候,讓 AI 「看一眼」網頁,確實比費盡心思去解析 HTML 原始碼要優雅、準確得多。