9 年後重讀深度學習奠基作之一:AlexNet(下)
上篇用第一遍建立大局觀;這篇進入 第二遍閱讀:把論文從頭到尾快速通讀一遍,目標不是「每個細節都懂」,而是:
- 把每段在做什麼,用一句話寫下來
- 找到作者真正想賣的技術點(以及他沒說清楚、但你應該圈起來的地方)
- 把「第三遍才要深挖」的問題列表化
第二遍的心法:讀的是作者的視角,不是背誦細節
第二遍最值錢的收穫,常常是「作者怎麼描述問題」與「作者如何安排證據」。
- 經典論文往往包含不少 時代性的工程細節,今天不一定需要照抄
- 但它們能讓你看見:當年什麼是瓶頸、什麼是被視為突破
Introduction 怎麼讀:把「故事」拆成三個主張
AlexNet 的 Introduction 基本上在說三件事(用今日語言重述):
- 任務很難:大規模多類別影像辨識需要很強的表示能力
- 模型要夠大:容量越大越可能過擬合或訓練不動
- 工程讓它能跑:資料、GPU、訓練技巧與架構設計一起把模型訓練起來
第二遍的做法是:每讀完一段,就寫下一句「這段在鋪哪個主張/證據」。
1) ReLU:它的價值不是神祕,而是「簡單、可訓練、跑得動」
把 ReLU 放在很前面,因為作者想強調「訓練速度/可行性」。
你在第二遍不必把「飽和/非飽和」全部弄懂,但要能記下:
- 作者把 ReLU 當成關鍵技術點
- 他用圖(訓練曲線)說服你「更快收斂」
- 真正的原因與完整比較,可能要靠第三遍補讀背景
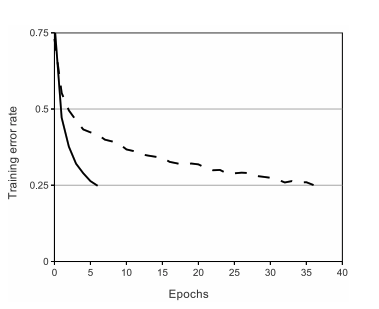
第三遍待辦(先圈起來)
- ReLU 為什麼會更好訓練?和梯度消失/初始化有什麼關係?
- AlexNet 的實驗設定是否足以支撐「ReLU 更快」這個因果結論?
2) 多 GPU 切分:重要的是「歷史瓶頸」,不是照抄切法
在 2012 年,單張 GPU 記憶體小,作者花了大量力氣把網路切到兩張卡上,這在論文敘事裡被包裝成一個重要貢獻。
但用今日視角讀第二遍,你可以把它當成:
- 瓶頸證據:當時硬體限制真的很強,逼出不少「能跑就好」的設計
- 可忽略細節:若你的目標不是復現到同樣硬體條件,切法本身不是方法論核心
一個有趣的歷史回音
這種切分可視為早期的 model parallel。它在一段時間不流行,但當模型更大(尤其在 NLP)又重新成為主流工具之一。
3) 架構圖怎麼讀:先讀「張量大小變化」,再讀「層的目的」
AlexNet 的圖很容易讓人迷失。第二遍建議只抓兩個層次:
- 形狀變化:(224 \times 224 \times 3\) 的輸入,經過卷積/步幅/池化後,空間解析度逐步下降、通道數逐步上升
- 功能分工:前面卷積抽特徵、後面全連接做分類,最後 softmax
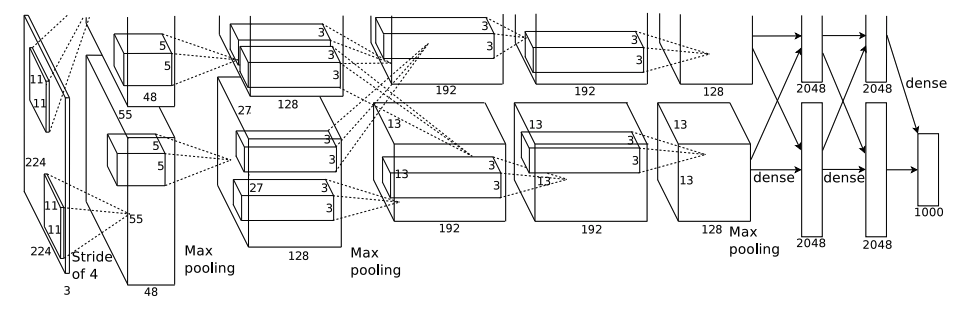
第二遍你要寫下來的兩句話
- 這是一個「五層卷積 + 三層全連接」的典型早期深網範式
- 它用大卷積核(如 11×11)與較大步幅(stride)快速降解析度,換取可訓練的計算量
4) 池化(Pooling)與 Overlapping pooling:知道它改了什麼就好
pooling/overlapping pooling,重點不是推導,而是:
- 它是對當時常見 pooling 做了小改動
- 作者宣稱有收益,你要把「改動點」記下來,等需要時再回補細節
5) 過擬合怎麼處理:資料增強 + Dropout + Weight decay
5.1 資料增強(Data augmentation):隨機裁切讓你「看到更多樣本」
第一個手法是:從 (256 \times 256) 隨機裁出 (224 \times 224) 的區塊當作訓練輸入。
這裡第二遍要掌握的是直覺:
- 同一張圖可以生成多個「視角」\n- 模型較不容易死背訓練資料的固定位置/構圖
5.2 色彩抖動(PCA color augmentation):知道「它動了顏色通道」即可
AlexNet 用 PCA 在 RGB 通道上做擾動。第二遍可以先記下:
- 這是對顏色分佈做隨機擾動\n- 目的是增加顏色/光照條件的多樣性
5.3 Weight decay(L2 正則)與 Momentum:當年主流的 SGD 配方
兩個值得你在筆記裡留下來的點:
- Weight decay 常被深度學習社群當作 L2 正則的實作語言\n- Momentum 變成後來很長一段時間的標配(即使當時有更多「花式加速法」)

6) 學習率策略:從「手動盯訓練」到「規律/平滑的 schedule」
AlexNet 時代常見做法是:從某個初始學習率開始,當驗證誤差不再下降就把學習率乘上 0.1(降低十倍)。
用今日視角讀第二遍,你可以把它理解成:
- 當時算力貴、工具鏈不成熟,很多策略靠人工監控\n- 後來才逐漸演變成固定節奏的 step decay,甚至更平滑的 cosine decay
小結:第二遍讀完,你應該留下的清單
把「你已懂的輪廓」和「第三遍要補的洞」分開寫,第二遍就很成功:
- 輪廓:ReLU、架構設計、資料增強、SGD 配方與學習率下降\n- 洞(第三遍):ReLU 更快的原因、PCA 色彩抖動的具體做法、哪些工程細節對可複現真的重要\n- 系列下一篇預告:下一篇會把這些「洞」整理成可複現清單與檢查表,並補上哪些細節在今日其實可以替換成更穩定的現代做法
系列 看全部