9 年後重讀深度學習奠基作之一:AlexNet(上)
如果要選一篇「改變產業走向」的深度學習論文,AlexNet 幾乎永遠在清單最前排。它不只是一個當年刷榜的模型,更像是一個訊號:只要資料夠大、模型夠深、算力跟得上,神經網路可以在困難任務上壓過當時的主流方法。
李沐老師嘗試用一個更可複用的方式,帶你把 AlexNet(Krizhevsky et al., 2012)讀成自己的知識:先建立大局觀,再逐步深入。本文是上篇,聚焦在「第一遍閱讀」:只看最能決定是否值得深挖的資訊。
本文補充內容參考:9年后重读深度学习奠基作之一:AlexNet【论文精读·2】(李沐老師論文精讀影片)所作筆記整理。
為什麼要在多年後重讀 AlexNet?
重讀經典有兩個價值:
- 把讀法練出來:用一個有歷史地位、但寫作風格也有明顯時代痕跡的論文,示範如何快速抓出重點。
- 用今日視角校準結論:再經典的工作也有時代限制;我們要保留精髓,但也要能指出哪些說法其實只是「當時的合理推測」。
三遍讀論文法(這篇用得到的版本)
這個方法的核心精神是「越往後越貴」:越後面的閱讀越花時間,所以要先用最便宜的資訊做決策。
- 第一遍:只看標題、作者、摘要、最後段落(結論或討論),再掃一眼關鍵圖表與公式。
- 第二遍:快速通讀全文,建立段落目的與方法輪廓。
- 第三遍:針對你真的需要的部分深入推導、查背景、做實作或複現。
本文只涵蓋第一遍:你讀完應該能回答「這篇值不值得我進入第二遍」。
第一遍先看標題:它在告訴你「題目」與「方法」
AlexNet 的標題是:
ImageNet Classification with Deep Convolutional Neural Networks
只拆兩個關鍵詞就夠了:
- ImageNet Classification:當年的超大型影像分類資料集與競賽舞台(約 120 萬張訓練圖、1000 類別)。
- Deep Convolutional Neural Networks:卷積神經網路(CNN)在當時並不是所有機器學習研究者的共同語言,更別說「深」這件事。(當時產業界與學術界的主流,仍是 SVM 搭配 SIFT/HOG 等手工特徵(Hand-crafted features))
如果你對 CNN 不熟,第一遍完全看不懂模型結構圖很正常;第一遍要做的是「確認它要解決什麼問題、憑什麼值得你花時間」。
再看作者:這不是迷信,而是快速建立先驗
論文作者列(Alex Krizhevsky/Ilya Sutskever/Geoffrey E. Hinton)
第一作者是 Alex Krizhevsky,作者群包含 Ilya Sutskever 與 Geoffrey E. Hinton。以 2012 年的社群規模來說,作者資訊能快速給你兩個判斷:
- 這工作很可能與神經網路路線高度相關(Hinton 的研究脈絡非常明確)。
- 它可能更偏「效果與工程」而不是完整理論解釋(這點也確實反映在論文敘事上)。
作者不是用來「崇拜」,而是用來估計「你將要面對的寫作風格與證據形式」。
讀摘要:它在第一句就把賣點放在桌上
這篇論文的摘要非常直接,幾乎是技術報告式寫法:
- 我做了什麼:訓練了一個大型、深的 CNN 來做 ImageNet 分類(1000 類)。
- 我結果多好:在測試集上 top-1 與 top-5 錯誤率分別是 37.5% 與 17.0%(論文也會提到 2012 競賽 top-5 15.3% 的數字,差異來自評估設定與資料處理的細節)。
- 我的模型很大:約 6000 萬個參數、65 萬個神經元,5 個卷積層 + 3 個全連接層 + 最終 softmax。
- 我怎麼訓練得動:GPU 實作、用 dropout 做正則化。
第一遍讀摘要的重點不是背數字,而是抓出一句話結論:
這篇論文主張:在足夠困難、足夠大規模的資料集上,大而深的 CNN 能把影像分類的錯誤率顯著打下來。
直接跳到最後:它沒有「結論」,只有「討論」

AlexNet 沒有典型的結論段落,而是用「討論」收尾。第一遍閱讀時,你可以把討論當作「作者希望你帶走的幾句話」:
- 深度很重要:拿掉一層,表現會掉(作者用實驗觀察支持這點)。
- 但用今日視角補一句更精準的說法:表現下滑未必能單獨證明「深度是唯一關鍵」,因為也可能牽涉到超參數與配置;更完整的理解是「深度與寬度的配置都重要」。
- 不需要無監督預訓練也能做出很強的結果:在當時「深網難訓練」仍是常見直覺的背景下,這句話的份量很重。
- 也因此,整個領域在一段時間內更集中火力在有標註資料的監督式訓練與可擴展算力上。
- 算力、資料、訓練更久可能更好:對今日的讀者來說,這句話既像預言,也像提醒:它依賴工程條件,而不是單純的模型設計。
- 往影片(video)資料延伸:作者指出影片有時序訊息,但當時受限於算力與資料取得(版權等)而進展較慢。
第一遍要掃的圖:不用看懂架構,也要看懂「它在賣什麼」
逐字稿特別點出幾類圖對第一遍很有價值:

- 定性結果圖(top-5 預測示例):讓你直覺感受「在細粒度分類與多類別下,它能給出合理候選」。

- 相似度檢索示例(倒數第二層特徵):即使論文沒有大篇幅強調,這個觀察後來被證明非常關鍵:
CNN 學到的特徵表示(representation)能把語意相近的影像放在一起,成為可遷移的通用特徵。
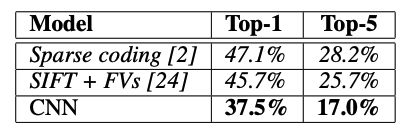
- 與前人方法的表格比較:它把論文的主賣點講清楚:我不只是贏,我是大幅領先。
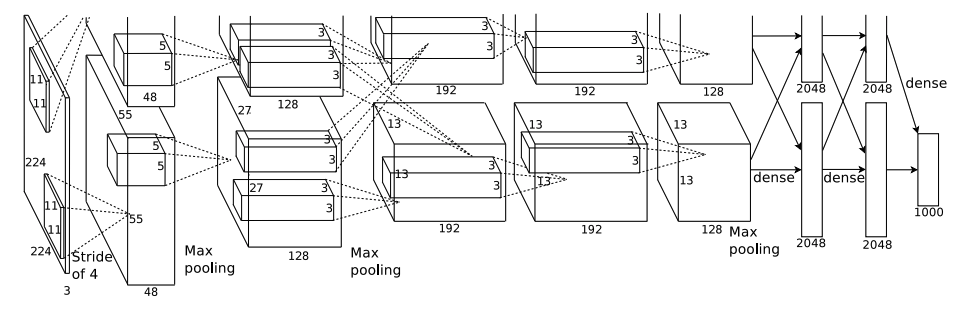
- 網路結構圖(block diagram):第一遍不懂沒關係;你只要先知道它是一個「多層卷積 + 池化 + 全連接」的堆疊式架構即可。
小結:第一遍讀完,你應該得到的三個判斷
如果你只做第一遍閱讀,理想的收穫是這三句話:
- 它解決什麼:在 ImageNet 這種大規模、高難度影像分類任務上,把錯誤率顯著打下來。
- 它憑什麼:大而深的 CNN + 可行的訓練工程(GPU、資料增強、ReLU、dropout 等)讓模型真正訓練得動且不易過擬合。
- 它留下什麼長期影響:不只是一個冠軍模型,而是把「表示學習」與「可擴展訓練」推到產業與學術的主航道上。
下篇(中/下篇)若要進入第二遍與第三遍,重點會落在:模型細節、訓練技巧到底各自貢獻多少、以及哪些結論在今日應該如何更新詮釋。
原始出處
- 論文:Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems (NeurIPS 2012).
https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf