Anthropic 最新研究:代理寫程式 (Agentic Coding) 的現狀與領域專業的持續價值
人類決定「做什麼」,AI 決定「怎麼做」:深度解析 40 萬次 Claude Code 互動數據

隨著 AI 代理(AI Agent)逐漸融入日常工作,自動化程式開發(Agentic Coding)也迎來了爆發式的成長。GitHub 上的代理活動自 2025 年末以來成長了兩倍,而 Claude Code 的用戶每週平均花費 20 小時在該工具上。
一個關鍵的問題浮現:沒有正式寫程式經驗的人,是否能夠成功引導代理完成複雜的技術工作? 而這些工具的快速普及與進步,對廣大的知識工作者又意味著什麼?
為了回答這些問題,Anthropic 發表了最新研究 《Agentic coding and persistent returns to expertise》,基於 2025 年 10 月至 2026 年 4 月間約 40 萬次的 Claude Code 互動會話(涵蓋 23.5 萬名使用者),進行了隱私保護分析(privacy-preserving analysis)。研究結果不僅揭示了代理工具的實際使用狀況,更為未來勞動力市場的轉型提供了早期信號。
核心發現 (Key Findings)
- 人類決定「做什麼」,Claude 決定「怎麼做」:在典型的會話中,人類做出了大部分的規劃決策(Planning),而 Claude 承擔了大部分的執行決策(Execution)。使用者具備的領域專業知識越豐富,Claude 在每次指令中所完成的工作量就越大。
- 「領域專業」決定成功率,而非「寫程式能力」:在程式開發任務中,各大非軟體職業的平均成功率,幾乎與軟體工程師相當。成功(達成使用者預期目標,並有測試通過或提交紀錄等可驗證證據)與使用者的領域專業程度呈現正相關。
- 工作模式的演進:走向端到端:在觀察的 7 個月內,花在 Debug(修復)的會話比例下降了近一半,使用行為逐漸轉向更端到端的代理操作,包含:部署與運行程式、數據分析、以及撰寫非程式碼文件。同時,任務的估計經濟價值平均提升了約 25%。
工作分工:人類與 Claude 的合作模式
大家用 Claude Code 來做什麼?
Anthropic 將所有互動會話分類為 9 大工作模式:
- 撰寫/維護程式碼 (4 類):構建新功能 (Building)、修復錯誤 (Fixing)、測試程式 (Testing)、編排自動化 (Orchestrating)。
- 操作軟體 (1 類):部署、配置、監控系統 (Operating)。
- 分析與規劃 (2 類):理解現有系統 (Understanding)、在修改前進行規劃 (Planning)。
- 非程式碼任務 (2 類):數據分析 (Analyzing)、撰寫簡報等溝通文件 (Communicating)。
數據顯示,約 56% 的會話與直接處理程式碼相關(建構 25%、修復 26%、測試與編排 5%)。操作軟體佔 17%,規劃與探索佔 14%,而分析與寫作佔 13%。
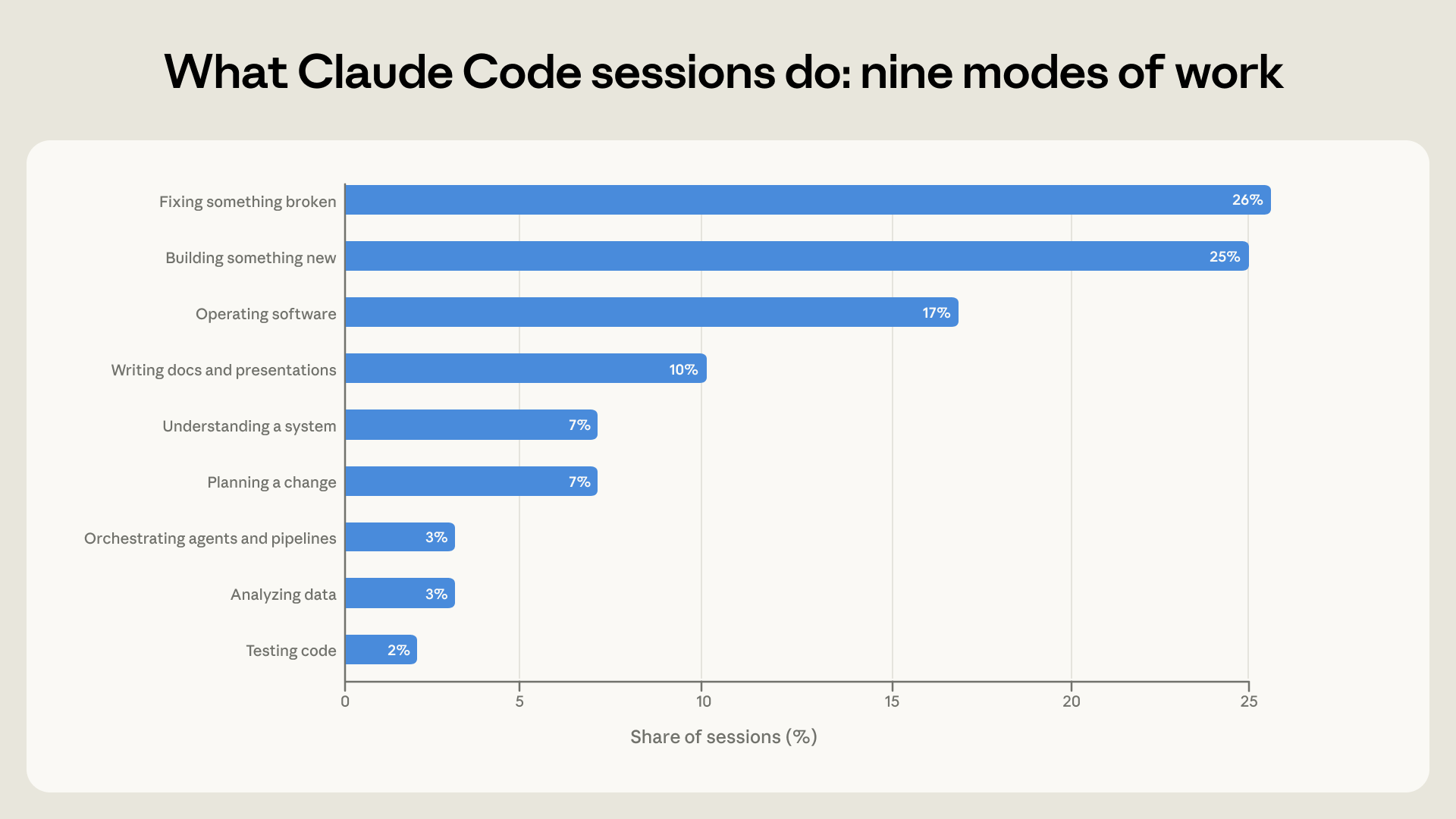 Figure 1: 九大工作模式。每一個互動會話都被歸類為最能描述其目標的單一模式。
Figure 1: 九大工作模式。每一個互動會話都被歸類為最能描述其目標的單一模式。
決策權歸屬:誰決定了什麼?
Claude Code 到底有多自主?在實際應用中,人類與 AI 之間存在明確的分工:
- 人類控制規劃:平均而言,人類做出了約 70% 的規劃決策(決定要做什麼、採取哪種方法、何時算完成)。
- Claude 負責執行:Claude 做出了約 80% 的執行決策(決定修改哪些檔案、寫什麼程式、用什麼語言、執行哪些命令)。
當人類保留較多執行決策時,Claude 每次回應的動作較少(約 8 個動作);但當 Claude 接管了更多執行細節,它的行動數量會顯著增加(約 16 個動作)。
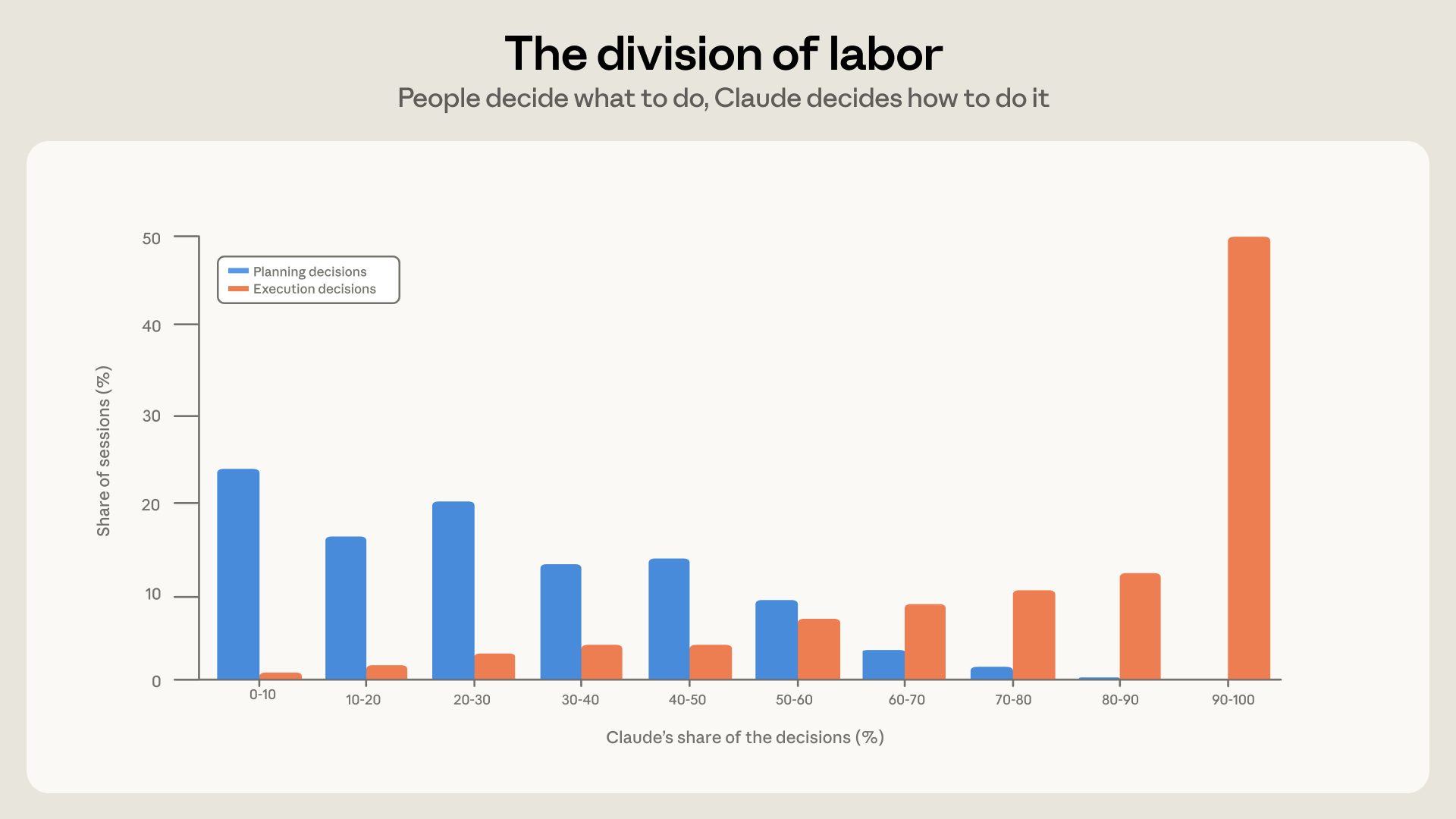 Figure 2: Claude 在規劃(左)與執行(右)決策中所佔的比例分佈。
Figure 2: Claude 在規劃(左)與執行(右)決策中所佔的比例分佈。
成功關鍵在於「領域專業」,而非「寫程式熟練度」
Anthropic 的研究指出一個令人振奮的現象:Claude 會根據使用者展現出的「專業程度」(Expertise)提供成比例的價值。
這裡的「專業程度」並非指使用者的職稱,而是特定於任務的專業知識(Task-specific expertise)。例如:一位資深軟體工程師若第一次詢問 Rust 的問題,他就是新手;但一位從未寫過 Python 的會計師,若能精準地告訴 Claude 月結帳腳本應包含哪些核對規則並抓出邊緣情況,他就是該任務的專家。
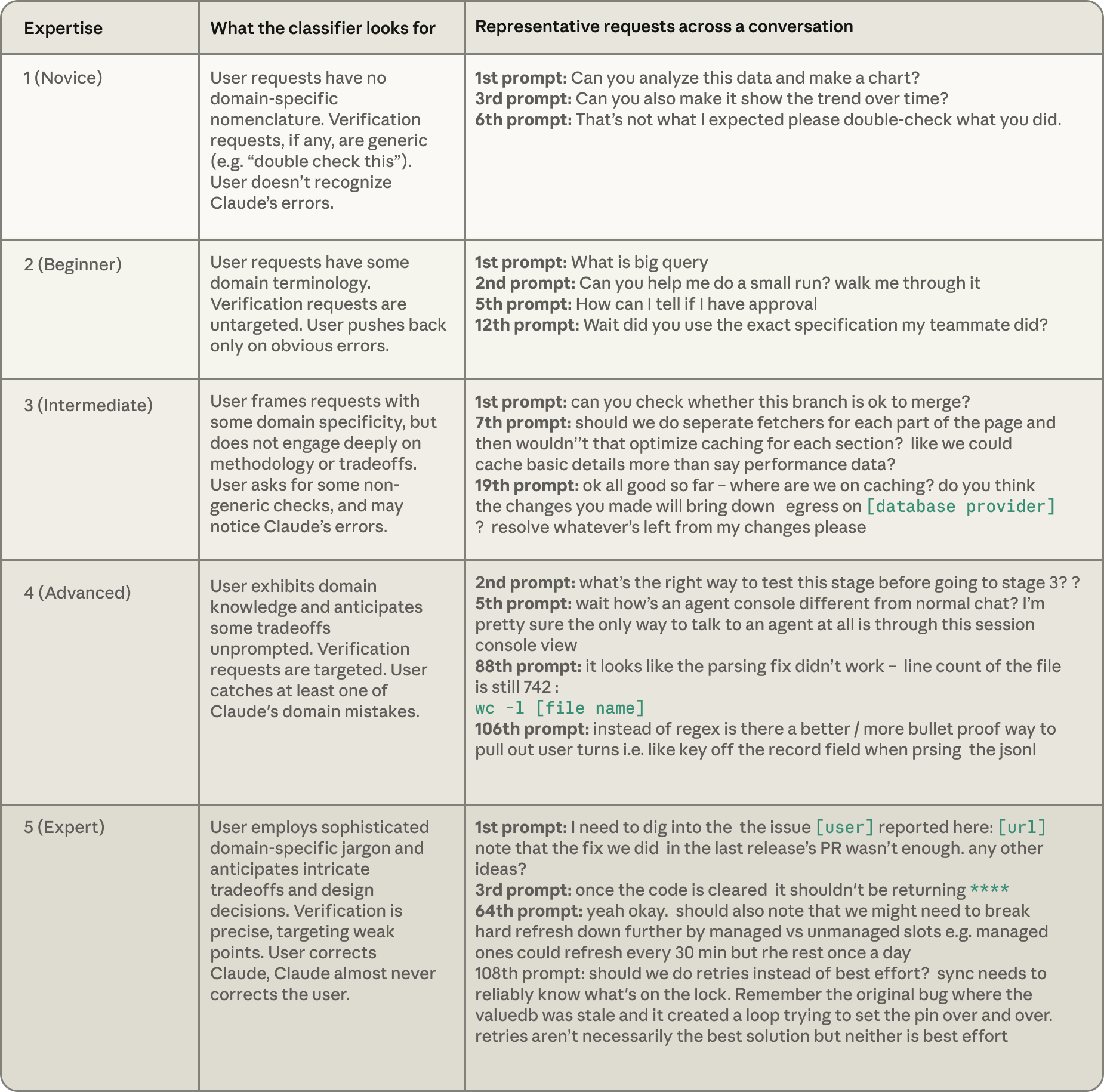 Table 1: 專業度分類器的定義與範例。新手給予泛泛的指示,而專家則展現出對代碼庫和技術環境的深入了解。
Table 1: 專業度分類器的定義與範例。新手給予泛泛的指示,而專家則展現出對代碼庫和技術環境的深入了解。
對於專家級使用者,Claude 每次提示會產出超過兩倍的動作(12 個)以及五倍的輸出量(3,200 字)。換言之,使用者能夠給予的脈絡與專業知識越深,Claude 的自動化「乘數效應」就越強。
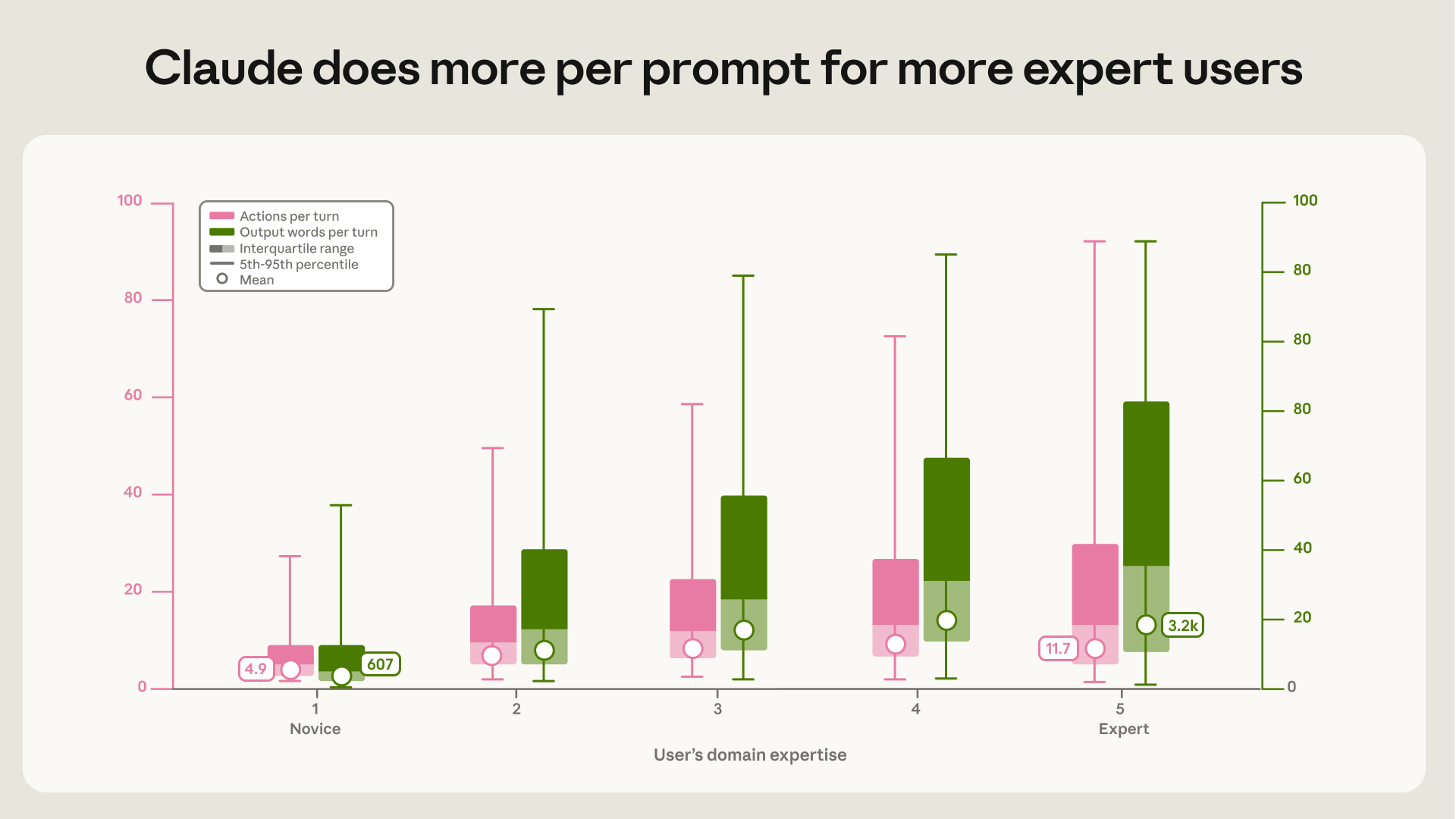 Figure 3: 隨著使用者專業度的提升,Claude 每次提示的動作數(左)與輸出字數(右)也顯著增加。
Figure 3: 隨著使用者專業度的提升,Claude 每次提示的動作數(左)與輸出字數(右)也顯著增加。
遇到困難時,專家更懂如何脫困
不論在哪種成功衡量標準下,專業知識都帶來了顯著差異:
- 新手使用者:嚴格驗證的成功率為 15%,至少部分成功的機率為 77%。
- 中級以上使用者:嚴格驗證的成功率達 28-33%,至少部分成功的機率高達 91-92%。
最值得注意的是,當專案遭遇困難(例如遇到報錯或測試失敗)時,約有 19% 的新手會直接放棄任務(0 行程式碼產出),而其他經驗等級的放棄率僅有 5-7%。這意味著,專業知識的價值不僅在於下指令,更在於能引導 Agent 回到正軌。
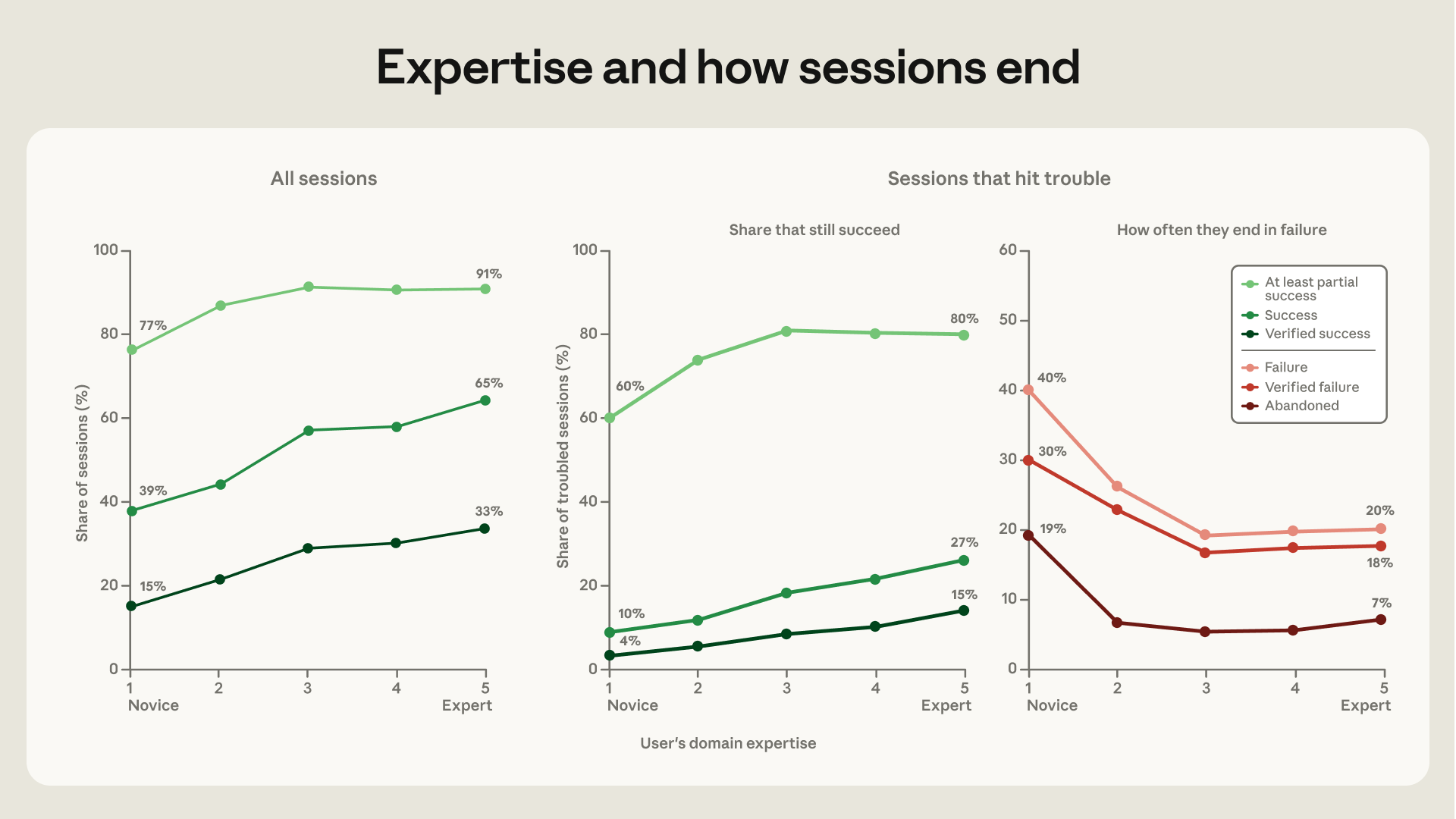 Figure 5: 使用者專業度與會話結果的關聯。左圖為所有會話,中右圖為遭遇困難時的會話結果。
Figure 5: 使用者專業度與會話結果的關聯。左圖為所有會話,中右圖為遭遇困難時的會話結果。
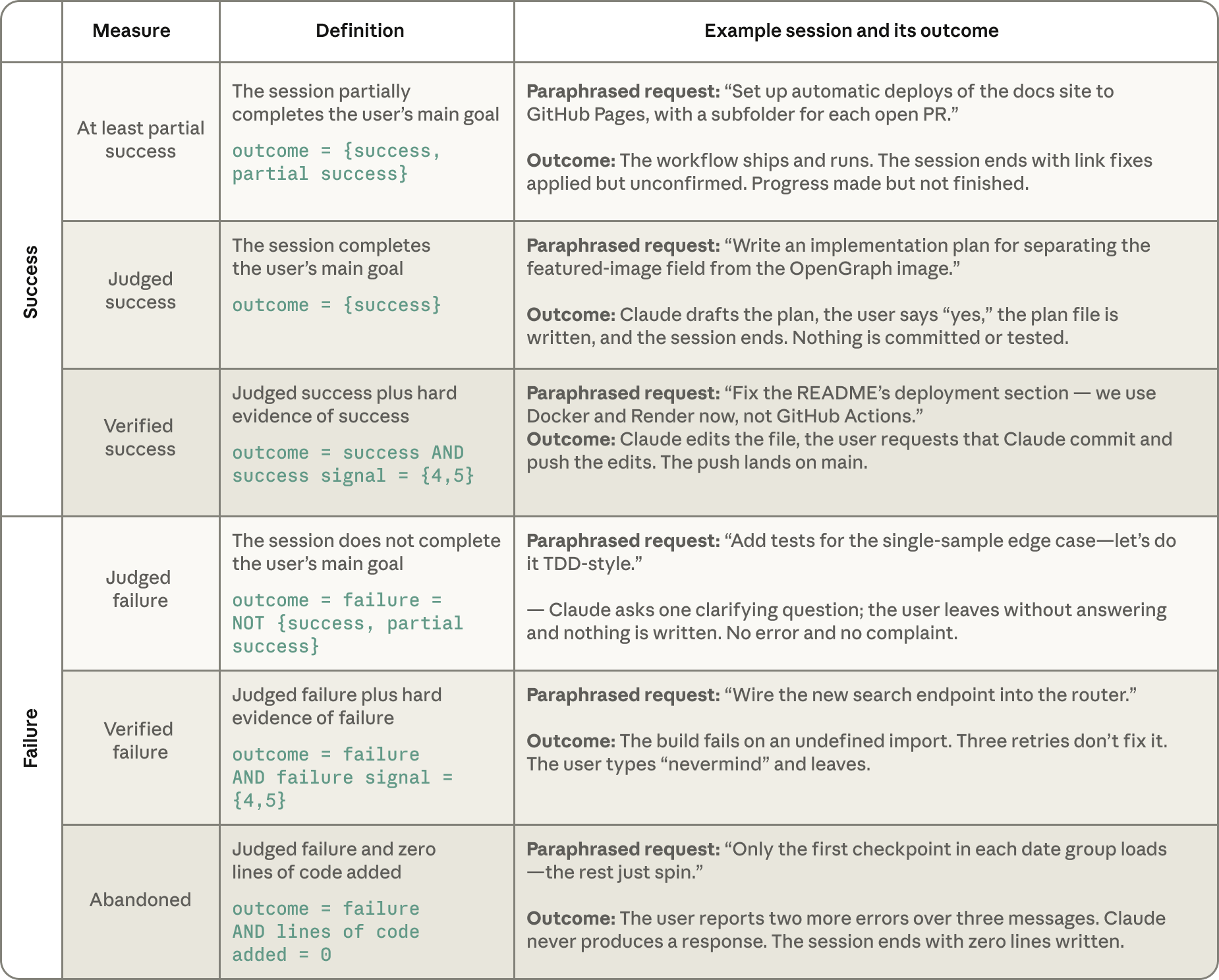 Table 2: 分類器中對成功與失敗的定義。
Table 2: 分類器中對成功與失敗的定義。
職業背景不再是障礙
在涉及修改程式碼的會話中,軟體相關職業的成功率約為 34%,而其他職業的成功率約為 29%。若放寬為「部分成功」,兩者的差距更是縮小到 89% vs 88%。
這表示,各大非軟體職業的成功率幾乎與軟體工程師不相上下(差距均在 7% 以內)。管理階層的驗證成功率甚至略高於軟體工程師,這可能反映了管理技能在「引導 AI 代理」上具有極高的遷移價值。
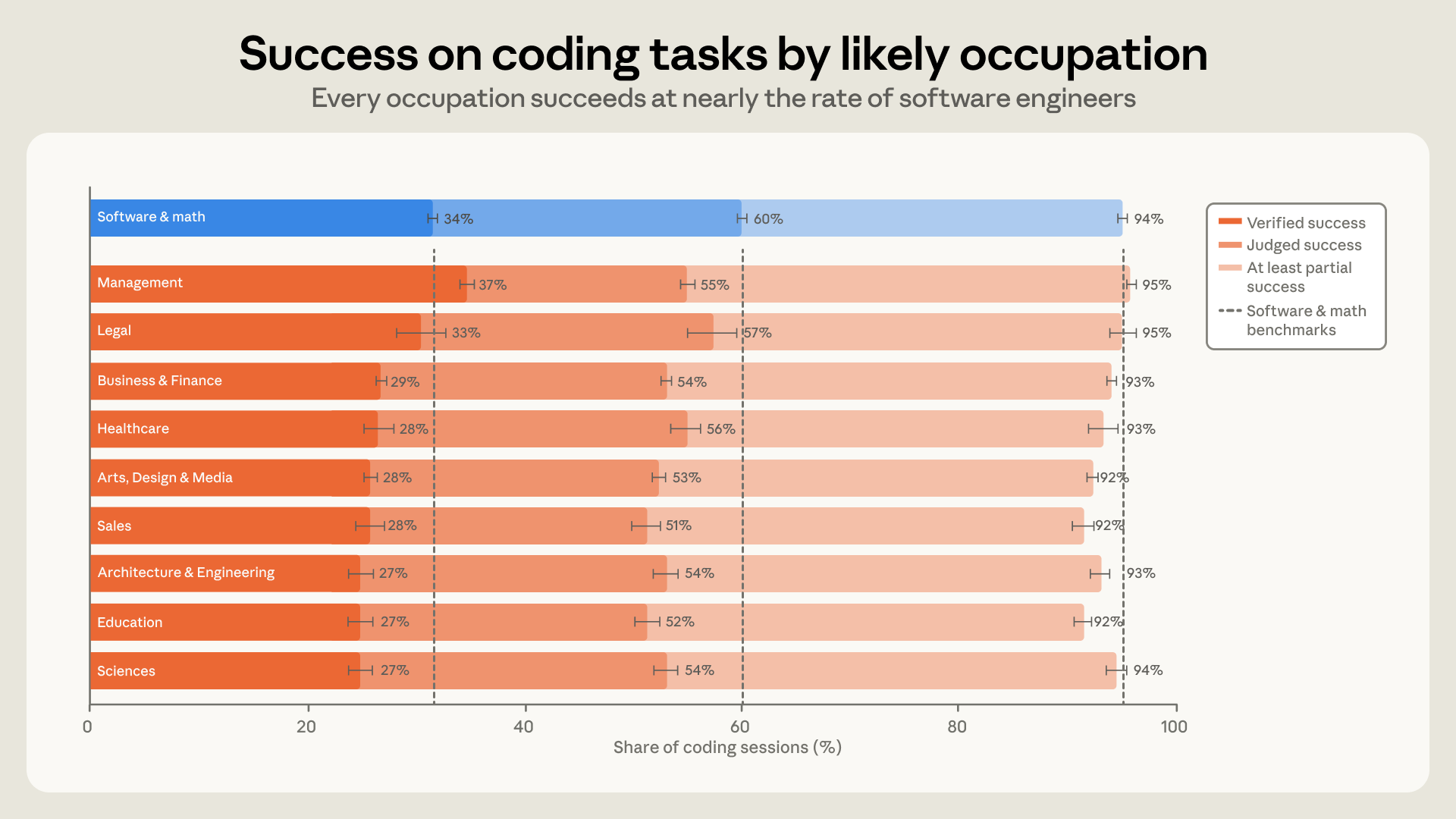 Figure 6: 十大主要職業群體在產生程式碼的會話中的驗證成功與判斷成功率。
Figure 6: 十大主要職業群體在產生程式碼的會話中的驗證成功與判斷成功率。
任務演變:更少 Debug,更高價值
從 2025 年 10 月到 2026 年 4 月的短短七個月內,Claude Code 的使用模式發生了實質的轉變:
- Debug 需求大減:用於修復錯誤 (Fixing) 的會話比例從 33% 降至 19%。
- 端到端應用激增:操作軟體、分析數據以及撰寫文檔的比例幾乎翻倍。
透過與自由工作者市場的報價數據比對, Anthropic 估計在過去的七個月中,Claude 處理的任務價值平均上升了約 27%。
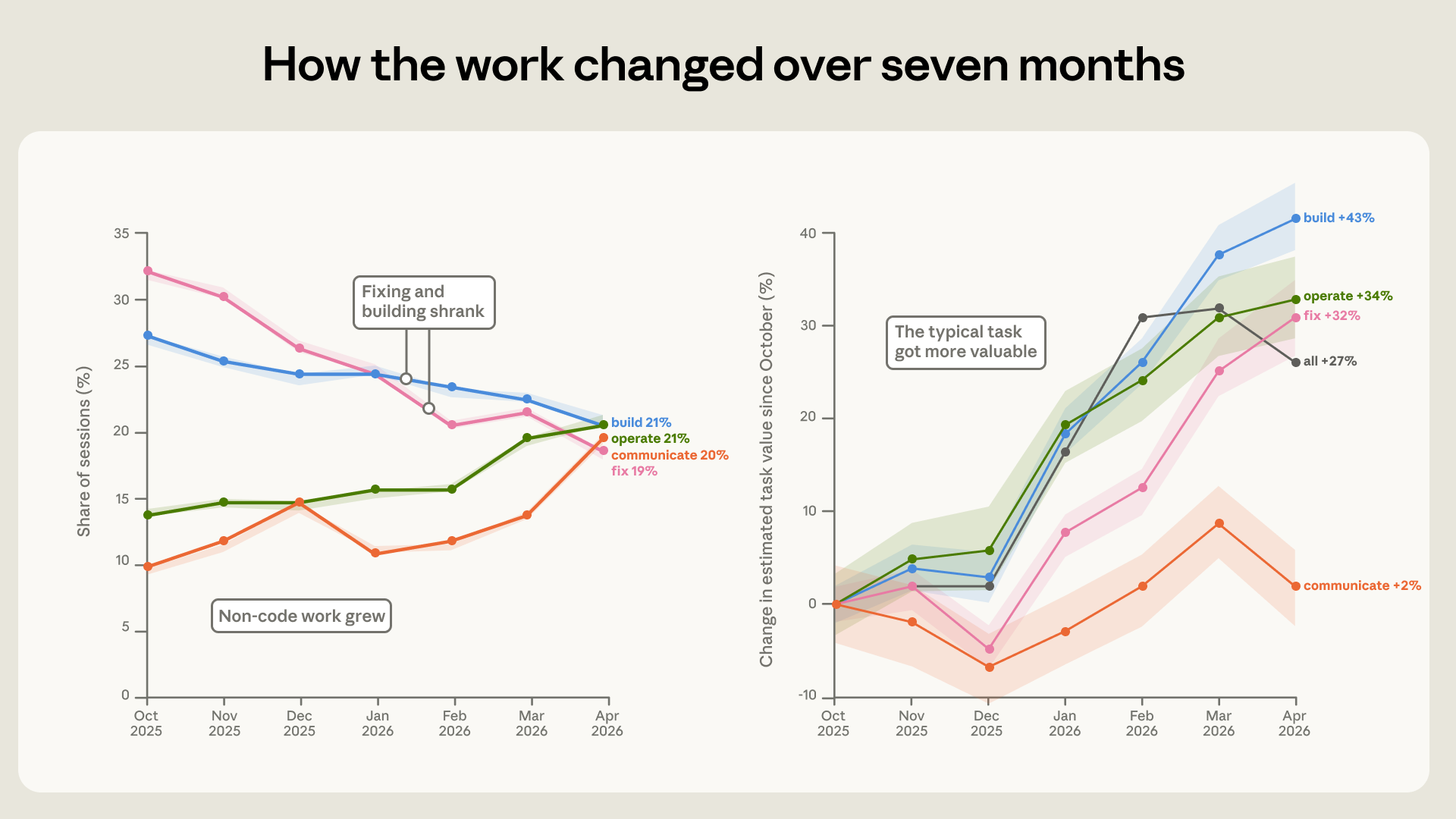 Figure 4: 2025 年 10 月至 2026 年 4 月,Claude Code 處理工作類型的比例變化,可見修復 Bug 的比例大幅下降。
Figure 4: 2025 年 10 月至 2026 年 4 月,Claude Code 處理工作類型的比例變化,可見修復 Bug 的比例大幅下降。
展望未來:AI 時代知識工作者的價值
這份研究報告為我們勾勒出一幅嶄新的未來勞動力圖景:
- 程式碼不再是高牆:在 Agentic Coding 工具的輔助下,「不會寫程式」不再是解決技術問題的障礙。軟體開發正在成為各行各業日常工作的一部分,而非單一職業的專利。
- 「領域專業」的黃金時代:能夠成功運用 AI 的關鍵,在於對問題本身擁有深刻的理解。使用者越懂業務邏輯與領域知識,AI 代理就能幫忙完成越多的實作苦工。
- 從「如何實作」轉向「要解決什麼問題」:隨著模型吸收了越來越多底層的實作(Implementation)工作,知識工作者的價值將完全取決於他們所帶來的規劃決策能力與領域洞察。
在代理寫程式的時代,AI 正在削弱單純程式語法的價值,卻極大地放大了領域專業的槓桿率。帶著對問題的深刻理解去指揮你的 AI,這才是未來的終極工作模式。
參考來源: Anthropic: Agentic coding and persistent returns to expertise