GraphRAG vs RAG:能力邊界與混合策略
論文深度解析報告:RAG vs. GraphRAG: A Systematic Evaluation and Key Insights
第一部分:第一次閱讀筆記(5-10 分鐘海選)
目標:鳥瞰論文,判斷價值。
1. 🧱 為什麼要讀這篇?解決什麼「坑」?(背景與動機) 隨著大語言模型(LLM)的發展,檢索增強生成(RAG)已成為標配,而結合知識圖譜的 GraphRAG 近期備受追捧(如微軟的 GraphRAG、HippoRAG 等)。然而,目前的學術界與產業界存在一個巨大的「坑」:缺乏統一的評估標準。各家 GraphRAG 論文往往使用自定義的資料集、特定的圖建構啟發式演算法以及不同的評估協議,導致開發者根本無從判斷:「GraphRAG 真的比標準 RAG 好嗎?什麼場景該用誰?引入圖結構的真實代價是什麼?」這篇論文正是為了解決這個「選擇困難症」與「效能迷思」而誕生的系統性 Benchmark。
2. 🛠️ 技術定位:它到底「做了什麼」?(核心貢獻與方法簡述) 這是一篇系統性基準測試(Benchmark)與實證分析論文。作者建立了一個嚴格控制變因的統一評估框架(相同的文本分塊、Embedding 模型、Reranker、生成模型),在問答(QA)和查詢驅動摘要(Query-based Summarization)兩大任務上,公平對比了標準 RAG 與四種主流 GraphRAG 變體(KG-based、Community-based、Text-centric、Hierarchical)。基於對比結果,作者進一步提出了結合兩者優勢的混合策略(Selection 與 Integration)。
3. 🔍 論文摘要精要(一句話總結與核心主張) 一句話總結:RAG 與 GraphRAG 並非「誰取代誰」的零和博弈,而是高度互補;RAG 稱霸單跳與細節事實檢索,GraphRAG 擅長多跳與全局推理,且 GraphRAG 的效能極度依賴圖建構品質,並伴隨顯著的運算與存儲成本。
4. 📊 第一遍必看圖表解析:系統表現與混合策略 為了直觀展示 RAG 與 GraphRAG 的對比以及混合策略的威力,我們直接看核心實驗結果圖:
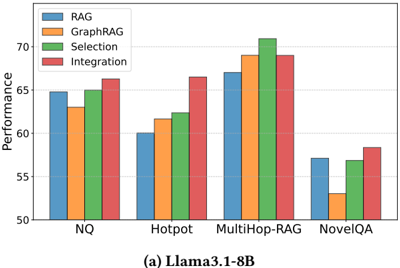
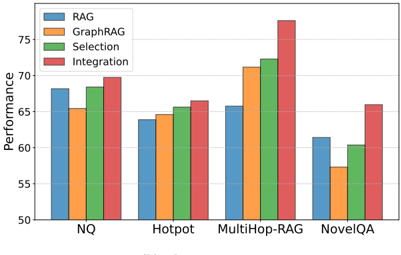 圖表解析 (Figure 3):這兩張圖展示了在不同規模模型(8B 與 70B)下,標準 RAG、GraphRAG 以及兩種混合策略(Selection 路由選擇、Integration 融合)在四大 QA 資料集上的整體表現。
圖表解析 (Figure 3):這兩張圖展示了在不同規模模型(8B 與 70B)下,標準 RAG、GraphRAG 以及兩種混合策略(Selection 路由選擇、Integration 融合)在四大 QA 資料集上的整體表現。
- 關鍵趨勢:沒有單一方法(純 RAG 或純 GraphRAG)能在所有資料集上通吃。例如在 NQ(單跳事實)上 RAG 佔優,而在 MultiHop-RAG(多跳推理)上 GraphRAG 佔優。
- 策略增益:無論是 8B 還是 70B 模型,Selection(綠柱)和 Integration(紅柱)策略幾乎在所有場景下都突破了單一方法的上限,證明了兩者結合的巨大潛力。
5. 💡 工程直覺:這東西離落地有多遠?(初步評估) 零距離,這是一份可以直接拿來指導企業級架構設計的避坑指南。 論文不僅給出了效能對比,還詳細拆解了建構時間、檢索延遲與存儲成本。對於工程師而言,這篇論文直接指明了落地路徑:不要盲目追求全盤 GraphRAG 化,基於 Query 意圖的路由分發(Selection)才是當下性價比最高的架構。
6. 🏁 第一遍速讀結論:三個關鍵判斷
- 解什麼:打破 GraphRAG 的神話,釐清 RAG 與 GraphRAG 的真實能力邊界與成本代價。
- 憑什麼:極其嚴謹的控制變因實驗,統一了 Chunking、Embedding、檢索預算(Top-k)與生成 LLM,讓對比絕對公平。
- 值得深讀嗎:強烈推薦深讀。特別是對於正在開發複雜 RAG 系統、猶豫是否要引入知識圖譜的演算法工程師與架構師,本文的 Failure Cases 和評估偏差分析價值連城。
第二部分:第二次閱讀精讀(30-60 分鐘精選)
目標:抓住方法、證據與對比,吃透技術細節。
1. 核心機制與推理鏈拆解 作者的推理鏈非常清晰:統一基準 -> 發現互補性 -> 提出融合方案 -> 揭示隱藏成本與評估缺陷。
- 四種 GraphRAG 門派的統一測試:
- KG-based (LlamaIndex):抽取三元組,檢索時遍歷子圖。
- Community-based (Microsoft GraphRAG):對圖進行層次化聚類,生成社區摘要。分為 Local Search(找實體與底層社區)和 Global Search(找高層全局摘要)。
- Text-centric (HippoRAG2):圖只是輔助,本質還是檢索原始 Text Chunk,利用圖結構引導分數傳遞。
- Hierarchical (RAPTOR):不依賴顯式 KG,而是對文本 Chunk 進行遞迴聚類與摘要。
- 混合策略的底層邏輯:
- Selection(選擇/路由):利用 LLM 的 In-context learning 能力,先判斷 Query 是「Fact-based(事實細節型)」還是「Reasoning-based(邏輯推理型)」。前者派發給 RAG,後者派發給 GraphRAG。這是一種典型的 Agentic 路由思維。
- Integration(融合):小孩子才做選擇,大人全都要。並行執行 RAG 和 GraphRAG,將兩邊檢索到的 Context 拼接後餵給 LLM。
2. 演算法與數學邏輯 本篇論文的重點不在於提出新公式,而在於實驗設計的嚴謹性。
- 公平的檢索預算:所有方法最終都限制在檢索 Top-k (k=10) 的證據單元,確保 LLM 接收到的 Context 長度在同一量級。
- 進階檢索增強:作者不僅測試了 Vanilla(原生)檢索,還疊加了 Reranking(重排序,使用 BAAI/bge-reranker-large) 和 IRCoT(交錯檢索與思維鏈)。這確保了結論不會因為「某個方法缺少 Reranker」而產生偏差。
3. 圖表深度解析與概念驗證
A. 互補性證明的鐵證:混淆矩陣
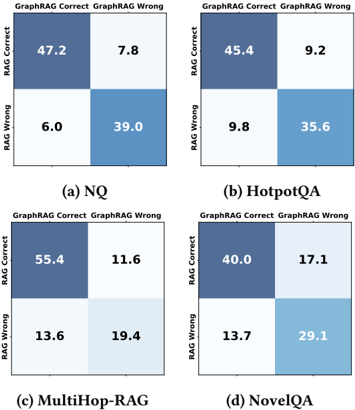 圖表概念說明 (Figure 2):這四張混淆矩陣圖展示了 RAG 與 GraphRAG 在不同資料集上的「答對/答錯」重疊情況。
圖表概念說明 (Figure 2):這四張混淆矩陣圖展示了 RAG 與 GraphRAG 在不同資料集上的「答對/答錯」重疊情況。
- 深度解析:注意左下角(RAG 錯但 GraphRAG 對)和右上角(RAG 對但 GraphRAG 錯)的比例。在 MultiHop-RAG (圖 c) 中,有 13.6% 的題目只有 GraphRAG 能解,同時有 11.6% 的題目只有 RAG 能解。這從根本上證明了兩者捕捉資訊的維度完全不同:RAG 捕捉字面語義與局部細節,GraphRAG 捕捉實體關聯與全局拓撲。這正是 Selection 策略能夠成功的數學基礎。
B. 進階推理策略的影響
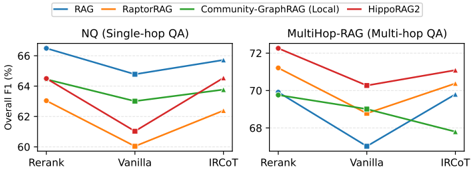 圖表概念說明 (Figure 1):展示了引入 Rerank 和 IRCoT 後,各個方法在單跳 (NQ) 和多跳 (MultiHop-RAG) 上的表現變化。
圖表概念說明 (Figure 1):展示了引入 Rerank 和 IRCoT 後,各個方法在單跳 (NQ) 和多跳 (MultiHop-RAG) 上的表現變化。
- 深度解析:Reranking 和 IRCoT 普遍能提升所有方法的表現。但關鍵在於相對排名的穩定性:即使加了最強的 IRCoT,標準 RAG 在單跳任務 (NQ) 上依然吊打 GraphRAG;而在多跳任務上,GraphRAG 依然保持領先。這說明 RAG 與 GraphRAG 的能力差異是架構基因決定的,無法單純靠後處理(Post-retrieval)來彌補。
C. 摘要任務中的「評估幻覺」:位置偏見 (Position Bias)
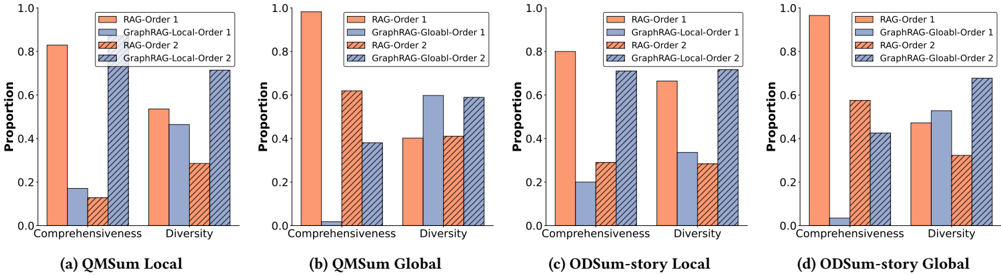
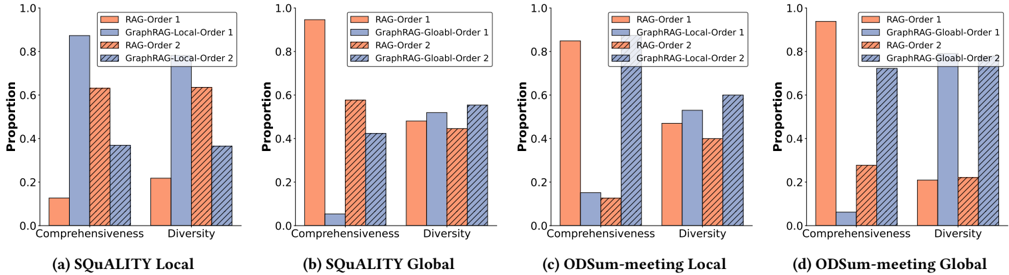 圖表概念說明 (Figure 4 & Figure 9):這兩張圖是全篇最犀利的打假環節。作者測試了使用 LLM 作為裁判(LLM-as-a-Judge)來評估摘要品質時,候選答案的「出場順序」對結果的影響。
圖表概念說明 (Figure 4 & Figure 9):這兩張圖是全篇最犀利的打假環節。作者測試了使用 LLM 作為裁判(LLM-as-a-Judge)來評估摘要品質時,候選答案的「出場順序」對結果的影響。
- 深度解析:微軟之前的 GraphRAG 論文聲稱其 Global Search 在摘要任務上碾壓 RAG,但那是基於 LLM 裁判的結果。本論文發現,LLM 裁判存在極其嚴重的 Position Bias。當 RAG 的答案放在前面(Order 1)時,LLM 壓倒性地認為 RAG 更好;當 GraphRAG 放在前面(Order 2)時,LLM 的偏好直接反轉。
- 客觀指標打臉:當切換回客觀的 ROUGE 和 BERTScore 指標(對比人類撰寫的 Ground Truth)時,標準 RAG 其實表現更好,因為人類寫的摘要往往包含具體細節,而 GraphRAG 的 Global Search 為了追求「全局多樣性(Diversity)」,丟失了太多細節(Comprehensiveness)。
4. 嚴格審視與邊界測試
- 致命弱點(Failure Cases):圖建構的覆蓋率 論文指出,KG-based GraphRAG 表現不佳的根本原因是實體遺漏。在 HotpotQA 中,只有 65.8% 的答案實體被成功抽取到知識圖譜中。如果圖建構這一步(通常依賴 LLM)漏掉了關鍵節點,後續的圖檢索演算法再精妙也是「巧婦難為無米之炊」。
- 成本與效率邊界(Trade-offs)
- 建構時間:KG-GraphRAG 和 Community-GraphRAG 的建構時間是標準 RAG 的數十倍(需消耗大量 LLM Token 進行抽取和聚類)。
- 檢索延遲:KG-GraphRAG 因為需要多跳遍歷,檢索極慢;但有趣的是,Community-GraphRAG 因為直接匹配預先算好的社區摘要,檢索速度反而比標準 RAG 還快。
- 存儲空間:Community-GraphRAG 需要存儲實體、關係、多層級社區摘要,存儲開銷最大。
- 極端情況:Context 過長導致的幻覺 在 Integration(融合)策略中,由於同時塞入了 RAG 和 GraphRAG 的檢索結果,Context 長度暴增。這導致 8B 小模型在處理「Null Query(無答案,應回答資訊不足)」時,準確率大幅下降(從 80%+ 掉到 50%),因為小模型容易被過長的上下文干擾而產生幻覺,強行編造答案。70B 模型則相對免疫。
5. 💡 總結與工程洞察 對於正在構建 RAG 系統的開發者,本論文提供了極具價值的實戰 Guideline:
- 不要盲目迷信 GraphRAG:如果你的業務場景主要是「查手冊」、「找具體條款」、「問特定數據」(Fact-based),標準 RAG + Reranker 依然是王者,且成本最低。
- 實作 Query Router 是當務之急:與其糾結選哪種檢索器,不如在系統最前端加一個輕量級的 LLM Router(即論文中的 Selection 策略),將複雜的跨文檔推理題交給 GraphRAG,將細節檢索題交給 RAG。這能達到效能與成本的最佳平衡。
- 圖建構的錢不能省:如果你決定上 GraphRAG,請務必使用最強的模型(如 GPT-4o)來進行實體與關係抽取。論文實驗證明,用 GPT-4o-mini 建構的圖會導致下游推理能力顯著下降。圖的品質決定了 GraphRAG 的天花板。
- 警惕 LLM 評估陷阱:在評估生成式任務(如摘要)時,絕對不能盲信 LLM-as-a-Judge。務必實作 Swap Test(交換順序測試)來消除位置偏見,並結合 ROUGE/BERTScore 等客觀指標進行交叉驗證。
原始出處
- 論文:GraphRAG vs RAG(arXiv)