概述
本專案提供 PDF 轉 Markdown 的完整解決方案:內建網頁前端與 FastAPI 後端 API,可上傳 PDF、即時預覽、左右分欄對比轉換結果,並一鍵下載 Markdown。採用 混合解析策略(PyMuPDF 快速路徑 + Gemini Vision)依頁面文字密度自動選擇最適方法,產出的 Markdown 可作為 RAG、知識庫與 LLM 解析的前置輸入。
為何選擇 Markdown?文件結構化的角色
在文件處理流程中,我們將 PDF、Word、PPT、圖片等非結構化文件轉為 Markdown,並非傳統「資料清洗」,而是 將非結構化內容標準化、可解析化 的前置工程。
- Markdown 保留結構 — 標題、段落、清單、表格、連結等輕量表示,在 token 成本與解析便利性之間取得平衡。
- LLM 原生理解 Markdown — 主流模型(GPT、Gemini)訓練時大量接觸 Markdown,能自然解析其結構與語意,適合作為「文件 → LLM」的中間層格式。
- Token 效率高 — 相較 PDF/XML/HTML 標記更少,有利 RAG、摘要與 QA。
- 結構化但不複雜 — 標題層級、表格、段落語意清晰,便於 RAG pipeline、embedding 與索引建立。
因此,文件結構化的核心,是將非結構化文件轉為 LLM 最能理解、最能高效解析的格式──Markdown。
功能重點
- PDF 上傳與轉換 — 支援多種 Prompt 樣板(簡報/表格/OCR/自訂),一鍵轉換。
- 即時預覽 — PDF 預覽、Markdown 渲染(如 Marked.js)、左右分欄對比。
- 一鍵下載 — 將轉換結果以 Markdown 檔下載。
- 可自訂 Prompt 樣板 — 內建
slide、table、ocr,或直接輸入自訂 prompt。 - 混合解析策略 — 文字密度高的頁面用 PyMuPDF 快速提取;文字密度低或含圖表的頁面用 Gemini Vision 結構化提取,系統依每頁自動選擇。
專案結構
pdf-to-markdown-converter/
├── app/
│ ├── main.py # FastAPI 主程式
│ ├── config.py # 配置(.env)
│ └── api/
│ └── pdf_convert.py # PDF 轉換 API
├── src/utils/
│ ├── pdf_parser.py # PDF 解析器(混合策略)
│ ├── pdf_cache.py # PDF 快取機制
│ ├── md_exporter.py # Markdown 匯出器
│ ├── prompts.py # Prompt 樣板管理
│ ├── logging_config.py # 日誌配置
│ └── retry.py # 重試機制
├── static/ # 前端介面
│ ├── converter.html # 主頁面
│ ├── css/style.css
│ └── js/main.js # 前端邏輯
├── requirements.txt
├── ENV_EXAMPLE.md # 環境變數範例
└── README.md技術架構
解析策略
- PyMuPDF 快速路徑 — 文字密度高的頁面直接提取文字,速度快、成本低。
- Gemini Vision — 文字密度低或含圖表/版面的頁面,由 AI 視覺模型做結構化提取。
- 系統依每頁 文字密度閾值(可配置
PDF_TEXT_DENSITY_THRESHOLD)自動選擇路徑。
主要依賴
- Web — FastAPI、Uvicorn
- PDF — PyMuPDF (fitz)、pdf2image、Pillow(系統需安裝 poppler)
- AI — google-generativeai(Gemini Vision)
- 配置 — pydantic-settings、python-dotenv
- 日誌 — loguru
- 前端 — 原生 HTML/CSS/JavaScript,Marked.js 渲染 Markdown
核心功能與機制
- 智能文字密度檢測、自動快取(可選,支援斷點續傳)
- 重試機制與斷路器、多進程圖片轉換 + 多線程 API 調用
- 速率限制保護、結構化日誌
環境變數與啟動
至少需設定 GOOGLE_API_KEY、GEMINI_MODEL(如 gemini-2.5-pro);可選包含 PDF 閾值、快取目錄、日誌等級、API 埠等,詳見 repo 內 ENV_EXAMPLE.md。
啟動方式:uvicorn app.main:app --reload --host 0.0.0.0 --port 8000。前端介面:http://localhost:8000/;轉換 API:POST /api/v1/convert-pdf(可帶 file、prompt_template)。
轉換範例
以下為簡報 PDF 經轉換後的範例:原始頁面擷圖與對應的 Markdown 輸出(保留頁碼、標題、列表與架構說明)。
轉換結果預覽
輸出 Markdown 片段(保留標題階層、列表與連結)
## Page 1
**Method:** gemini_vision
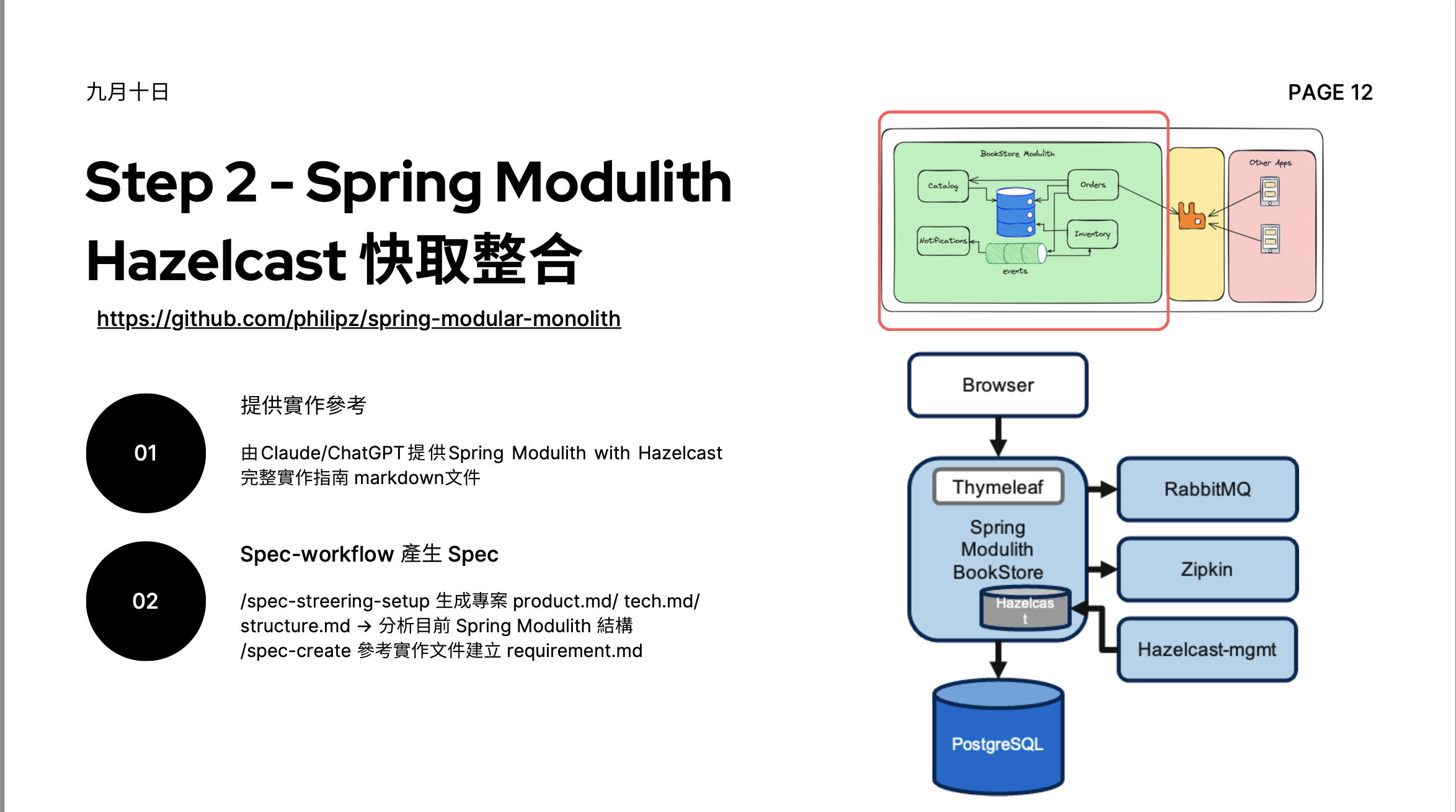
# Step 2 - Spring Modulith Hazelcast 快取整合
https://github.com/philipz/spring-modular-monolith
1. **提供實作參考**
- 由 Claude/ChatGPT 提供 Spring Modulith with Hazelcast 完整實作指南 markdown 文件。
2. **Spec-workflow 產生 Spec**
- `/spec-streering-setup` 生成專案 product.md/ tech.md/ structure.md,接著分析目前 Spring Modulith 結構。
- `/spec-create` 參考實作文件建立 requirement.md。
## 架構圖分析
### BookStore Modulith 內部結構
此架構圖展示了 BookStore Modulith 的內部模組及其互動關係。
- **主要模組**: Catalog, Orders, Notifications, Inventory
- **資料與事件**: 各模組均與中央資料庫和事件佇列互動。
- **外部整合**: BookStore Modulith 透過中介層與外部 "Other Apps" 通訊。使用場景
- RAG 系統 — 將 PDF 轉為 Markdown 後進行 embedding 與檢索。
- AI 分析 — 為 LLM 提供結構化文件內容。
- 文件處理 — 批次轉換 PDF,產出結構化內容。
- 知識庫構建 — 將非結構化文件轉為可索引的 Markdown 格式。
部署
專案可部署至 Render(提供 Dockerfile、render.yaml)。免費方案具 15 分鐘無活動休眠與每月 750 小時限制;可選付費方案以取得無休眠與更多資源。使用者可於前端輸入自己的 Gemini API key,或於 Render 環境變數設定後備 key。詳見 repo 內部署說明。