RAG-ANYTHING:多模態一體化 RAG 框架(雙圖構建與混合檢索)
第一部分:第一次閱讀筆記(5-10 分鐘海選)
1. 🧱 為什麼要讀這篇?解決什麼「坑」?(背景與動機)
目前的 RAG(檢索增強生成)系統存在一個致命的「模態盲區」:它們幾乎都假設知識庫是純文本。然而,真實世界的硬核文檔(如學術論文、財務報表、醫療報告)充滿了圖表、複雜表格和數學公式。 現有做法通常是粗暴地將這些多模態內容「壓扁」成純文本(例如用 OCR 硬轉),這會導致嚴重的結構與空間語義丟失。這篇論文就是要填平這個坑,讓 RAG 系統能真正看懂並檢索「圖、表、公式、文」交織的複雜文檔。
2. 🛠️ 技術定位:它到底「做了什麼」?(核心貢獻與方法簡述)
這是一篇提出多模態統一 RAG 框架的系統性論文。 它不依賴單一的向量檢索,而是首創了**「雙圖構建」(Dual-Graph Construction)**策略:
- 構建一個保留圖表/表格空間與從屬關係的「跨模態知識圖譜」。
- 構建一個傳統的「純文本知識圖譜」。
- 將兩者融合,並結合**「跨模態混合檢索」**(圖譜結構導航 + 向量語義匹配),讓 LLM 能夠在長篇多模態文檔中進行精準的多跳推理(Multi-hop reasoning)。
3. 🔍 論文摘要精要
一句話總結:RAG-Anything 是一個將多模態內容視為一等公民的統一框架,透過雙圖架構與混合檢索,徹底解決了長篇複雜文檔中跨模態證據碎片化導致的檢索失效問題。 核心主張:放棄將多模態轉為純文本的降維打法,改用「實體關聯圖譜」來保留多模態內容的結構上下文,才是通往真實世界 RAG 的唯一解。
4. 📊 第一遍必看圖表解析:系統架構鳥瞰
以下是 RAG-Anything 的核心系統架構圖,完美展示了其資料流向:
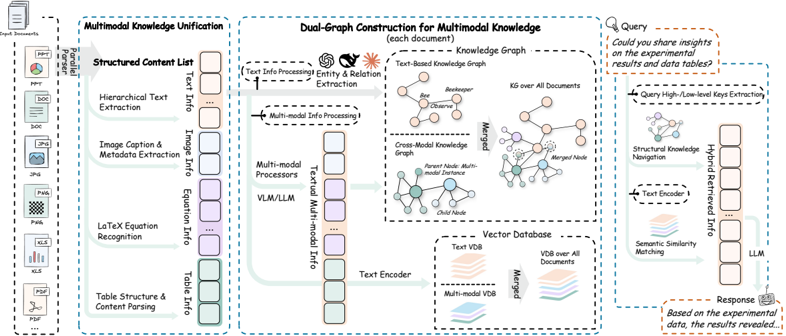
架構拆解:
- 左側 (Multimodal Knowledge Unification):先用解析器(如 MinerU)將 PDF 拆解成原子化的內容塊(文本、圖片、公式、表格),並保留層級關係。
- 中間 (Dual-Graph Construction):這是核心靈魂。上方走傳統 NLP 提取「文本知識圖譜」;下方用 VLM(視覺語言模型)提取圖片/表格中的實體與關係,構建「跨模態知識圖譜」。最後透過實體對齊(Entity Alignment)將兩張圖合併,並全部向量化存入 Vector DB。
- 右側 (Query & Hybrid Retrieval):當用戶提問時,系統同時進行「結構化圖譜導航」(找關聯)與「語義相似度匹配」(找相似),最後將檢索到的圖文 Context 餵給 VLM 生成答案。
5. 💡 工程直覺:這東西離落地有多遠?(初步評估)
非常接近落地,且極具商業價值。
- 開源友好:作者已開源代碼,底層依賴現有的解析工具(MinerU)和主流 LLM/VLM API。
- 模組化高:解析、圖譜構建、檢索是解耦的,企業可以替換成自家的 Parser 或 Graph DB。
- 成本考量:構建跨模態圖譜需要頻繁呼叫 VLM(如 GPT-4o-mini),Index 階段的 Token 成本和時間開銷會比傳統 RAG 高出一個數量級,適合用於高價值、低更新頻率的企業級知識庫(如財報庫、專利庫)。
6. 🏁 第一遍速讀結論
- 解什麼:真實世界複雜文檔(圖、表、文混排)的精準檢索與問答。
- 憑什麼:雙圖融合架構(保留了視覺與表格的結構語義)+ 混合檢索機制。
- 值得深讀嗎?:絕對值得。特別是對於正在開發企業級 RAG、金融研報分析、學術文獻問答系統的工程師與研究員,這篇論文提供了極佳的架構參考。
第二部分:第二次閱讀精讀(30-60 分鐘精選)
1. ⚙️ 核心機制:深入拆解底層邏輯
RAG-Anything 的成功建立在對「多模態內容」的重新定義上。它不再把圖片當作孤立的附檔,而是將其視為圖譜中的「節點」。
- 多模態知識統一化 (Unification): 將文檔拆解為 $c_j = (t_j, x_j)$,其中 $t_j$ 是模態(text, image, table…),$x_j$ 是內容。關鍵在於保留了「圖片與其 Caption」、「表格與其上下文」的綁定關係。
- 雙圖構建 (Dual-Graph Construction):
- 跨模態圖譜:對於非文本(如圖片),系統會截取其前後文(Context Window),讓 VLM 生成詳細描述與實體摘要。接著,以該圖片為「錨點節點 (Anchor Node)」,將提取出的內部實體(如圖表中的 X軸、Y軸、圖例)透過
belongs_to邊連接起來。 - 文本圖譜:類似 GraphRAG 的做法,提取文本中的實體與關係。
- 圖譜融合:透過實體名稱(Entity names)作為 Key,將兩張圖無縫縫合。這使得系統可以從「文本實體」順藤摸瓜找到「圖片實體」。
- 跨模態圖譜:對於非文本(如圖片),系統會截取其前後文(Context Window),讓 VLM 生成詳細描述與實體摘要。接著,以該圖片為「錨點節點 (Anchor Node)」,將提取出的內部實體(如圖表中的 X軸、Y軸、圖例)透過
2. 🧠 檢索/運算演算法:混合檢索機制
論文提出了一套極為優雅的 Cross-Modal Hybrid Retrieval 演算法:
- 模態感知查詢編碼:先分析 User Query 是否包含強烈的模態意圖(例如提到「根據圖表…」或「財報表格中…」),並將 Query 向量化。
- 雙軌檢索並行:
- 軌道 A:結構化知識導航 (Structural Navigation):利用精確的實體匹配進入圖譜,然後向外擴展(Multi-hop),找出隱含的結構關聯。
- 軌道 B:語義相似度匹配 (Semantic Matching):傳統的 Dense Vector 檢索,找出字面上不完全匹配但語義相關的 Chunk。
- 多信號融合打分 (Multi-Signal Fusion Scoring):將圖譜拓撲重要性、向量相似度、以及 Query 的模態偏好進行加權融合,得出最終的 Top-K 候選池。
- 視覺還原 (Dereferencing):在最後生成答案前,系統會將檢索到的「圖片描述文本」替換回「真實的原始圖片」,連同文本 Context 一起餵給 VLM 進行最終推理。
3. 📈 實戰表現與數據分析
論文在 DocBench 和 MMLongBench 兩個高難度資料集上進行了測試,結果非常驚艷。
亮點一:長文檔的統治力
傳統 RAG 在文檔變長時效能會斷崖式下跌,但 RAG-Anything 展現了極強的韌性。
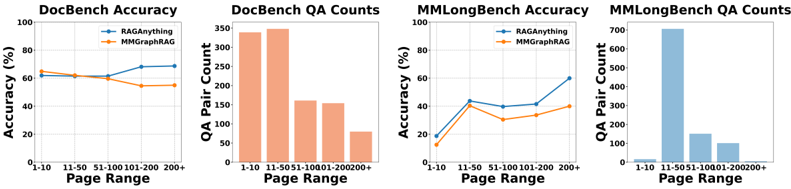 數據洞察:如上圖所示,當文檔長度超過 100 頁時,RAG-Anything 與 SOTA 模型(MMGraphRAG)的差距拉大到 13 個百分點以上(68.2% vs 54.6%)。這證明了「圖譜結構」在跨頁面、跨模態尋找碎片化證據時的絕對優勢。
數據洞察:如上圖所示,當文檔長度超過 100 頁時,RAG-Anything 與 SOTA 模型(MMGraphRAG)的差距拉大到 13 個百分點以上(68.2% vs 54.6%)。這證明了「圖譜結構」在跨頁面、跨模態尋找碎片化證據時的絕對優勢。
亮點二:消融實驗 (Ablation Study) 證明圖譜的必要性 拔掉圖譜構建(Chunk-only)後,準確率從 63.4% 暴跌至 60.0%。這說明傳統的 Chunking 切塊法根本無法處理多模態的複雜邏輯。
亮點三:空間與結構感知能力(案例對比) 為什麼圖譜這麼重要?請看以下兩個真實案例:

- 多面板圖表 (Multi-panel Figure):在上圖中,GPT-4o-mini 和其他 Baseline 把整張圖混為一談。RAG-Anything 因為在圖譜中建立了「子圖 (a) 屬於 Style Space」的明確邊界(Edges),成功避開了相鄰圖表的干擾,給出正確答案。

- 複雜財務表格 (Financial Table):在上圖中,要找 2020 年的 Wages。傳統 RAG 把表格壓成純文本後,年份和數字的對齊全亂了。RAG-Anything 透過
row-of和column-of的圖譜關係,精準定位到行列交叉點的數值(26,778)。
4. ⚠️ 嚴格審視:局限性與失敗案例 (Failure Cases)
這篇論文非常誠實地在附錄 (A.5) 探討了系統的失敗案例,這也是目前所有多模態 RAG 的通病:
風險一:跨模態對齊的「文本偏見」(Text-Centric Bias)
 如上圖所示,即使 Query 明確要求看「Figure 3」,系統有時仍會被周圍相似的「文本描述」吸走注意力,導致檢索到錯誤的文本證據,而忽略了圖片本身傳遞的精確結構順序(由下到上)。這顯示 VLM 在融合圖文時,仍存在嚴重的「重文輕圖」偏見。
如上圖所示,即使 Query 明確要求看「Figure 3」,系統有時仍會被周圍相似的「文本描述」吸走注意力,導致檢索到錯誤的文本證據,而忽略了圖片本身傳遞的精確結構順序(由下到上)。這顯示 VLM 在融合圖文時,仍存在嚴重的「重文輕圖」偏見。
風險二:非標準/模糊表格的結構崩壞
 如上圖,當遇到排版極度不規則的表格(如:缺乏明確分隔線、合併儲存格邏輯混亂)時,底層的 Parser 會解析失敗。「Garbage in, garbage out」,錯誤的解析會生成錯誤的圖譜節點與邊,導致所有依賴圖譜的 Baseline(包含 RAG-Anything)全軍覆沒。
如上圖,當遇到排版極度不規則的表格(如:缺乏明確分隔線、合併儲存格邏輯混亂)時,底層的 Parser 會解析失敗。「Garbage in, garbage out」,錯誤的解析會生成錯誤的圖譜節點與邊,導致所有依賴圖譜的 Baseline(包含 RAG-Anything)全軍覆沒。
5. 💡 總結與工程洞察:給開發者的具體建議
- Graph + Vector 是複雜 RAG 的終極解法: 如果你正在處理研報、論文、說明書,請停止單純的 PDF 轉 TXT + 向量檢索。引入 Graph 結構來保留「圖片-圖說-正文」以及「表格-表頭-單元格」的關聯,是提升準確率的唯一途徑。
- Parser(解析器)決定了系統的上限: RAG-Anything 的強大建立在 MinerU 等優秀解析工具的基礎上。在工程實踐中,你應該把 50% 的精力花在「如何完美地把 PDF 拆解成帶有層級關係的 Markdown/JSON」,而不是盲目調優檢索演算法。
- Prompt Engineering 的結構化:
論文中用來提取圖片/表格實體的 Prompt 非常值得借鑒(見附錄)。他們強制 VLM 輸出嚴格的 JSON 格式,包含
detailed_description、entity_name、entity_type和summary,這保證了圖譜構建的穩定性。 - 成本控制策略: 在落地時,不需要對所有圖片進行 VLM 實體提取。可以先用輕量級模型過濾掉裝飾性圖片(如 Logo、背景圖),只對包含高密度資訊的圖表(Charts, Diagrams)進行圖譜化,以平衡成本與效能。
原始出處
- 論文:Guo, Ren, Xu, Zhang, Huang. RAG-ANYTHING: ALL-IN-ONE RAG FRAMEWORK. arXiv:2510.12323(2025)
- 參考連結:arXiv PDF
- 代碼:HKUDS/RAG-Anything