Beyond RAG for Agent Memory:從解耦到聚合
論文深度解析報告:Beyond RAG for Agent Memory: Retrieval by Decoupling and Aggregation
第一部分:第一次閱讀筆記(5-10 分鐘海選)
目標:鳥瞰論文,判斷價值。
1. 🧱 為什麼要讀這篇?解決什麼「坑」?(背景與動機) 在開發 LLM Agent 時,我們通常會直接套用標準的 RAG(檢索增強生成)架構來處理 Agent 的長期記憶。然而,這是一個巨大的「坑」。標準 RAG 假設檢索庫是龐大且異質的(例如維基百科),但 Agent 的記憶是一個有界限、高度連貫且充滿重複內容的對話流。 在這種情況下,傳統的固定 Top-$k$ 相似度檢索會導致「崩潰」:它會抓出一大堆語意相似但內容冗餘的對話片段。為了解決冗餘,現有做法通常會加入後處理的「剪枝(Pruning)」機制,但對話記憶中的因果關係和時間線往往是交織在一起的,粗暴的剪枝極易破壞推理所需的前提條件(Prerequisites),導致模型產生幻覺或回答不完整。
2. 🛠️ 技術定位:它到底「做了什麼」?(核心貢獻與方法簡述) 本文提出了一個名為 xMemory 的全新 Agent 記憶架構,主張記憶檢索應該從「解耦到聚合(Decoupling to Aggregation)」。 它放棄了對原始文本塊的直接比對,而是:
- 建構四層次記憶階層:將原始訊息(Messages)總結為情節(Episodes),從情節中提取可複用的語意節點(Semantics),最後將語意分群為主題(Themes)。
- 動態結構優化:在寫入記憶時,透過一個結合「稀疏性」與「語意連貫性」的目標函數,動態拆分或合併主題,維持記憶圖譜的健康度。
- 由上而下的自適應檢索:檢索時先在主題與語意層面挑選具備多樣性的「代表節點」,接著向下展開到情節與原始訊息,且僅在能降低 LLM 不確定性時才納入底層細節,從而嚴格控制冗餘。
3. 🔍 論文摘要精要 透過將高度相關的對話流解耦為四層次語意結構,並採用由上而下的不確定性感知檢索,xMemory 成功解決了傳統 RAG 在 Agent 記憶中容易導致的「冗餘檢索」與「上下文斷裂」問題,在提升回答品質的同時大幅降低了 Token 消耗。
4. 📊 第一遍必看圖表解析
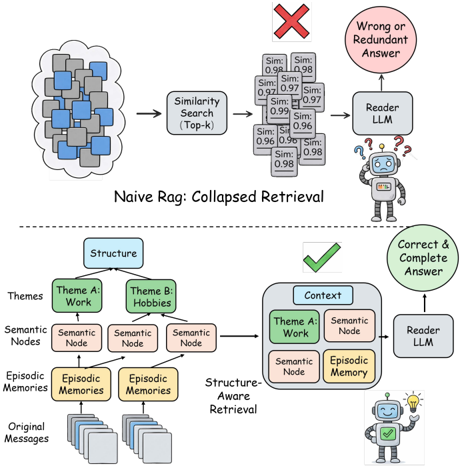 圖表解析:Figure 1 完美揭示了核心痛點與解決方案。
圖表解析:Figure 1 完美揭示了核心痛點與解決方案。
- 上半部(Naive RAG):面對高度相關的記憶流,Top-$k$ 相似度檢索會陷入局部密集區域(Collapsed Retrieval),返回大量相似度極高(如 0.98, 0.97)但內容重複的 Chunk,導致 LLM 獲得錯誤或冗餘的上下文。
- 下半部(xMemory):將記憶結構化為 Themes $\rightarrow$ Semantic Nodes $\rightarrow$ Episodic Memories $\rightarrow$ Original Messages。檢索時具備「結構感知(Structure-Aware)」,能夠跨主題(Theme A, Theme B)精準提取不重複的語意節點與情節,提供 LLM 正確且完整的解答依據。
5. 💡 工程直覺:這東西離落地有多遠?(初步評估) 非常近,且具備極高的商業價值。 這套框架完全建立在現有的 LLM 與 Embedding 模型之上(實驗使用了 Qwen3, Llama-3.1, GPT-4/5 等),不需要重新訓練底層模型。更重要的是,它在提升準確率(BLEU/F1)的同時,顯著降低了每次 Query 的 Token 消耗(約減少 30%-40%)。對於需要長期記憶的 AI 陪伴、客服或個人助理產品來說,這意味著直接降低了 API 呼叫成本。
6. 🏁 第一遍速讀結論:三個關鍵判斷
- 解什麼:Agent 長期記憶系統中,傳統 RAG 帶來的「檢索冗餘」與「剪枝導致的邏輯斷裂」問題。
- 憑什麼:四層次記憶解耦架構、基於資訊理論的動態 Split/Merge 機制、雙階段(代表性選擇 + 不確定性展開)檢索演算法。
- 值得深讀嗎:強烈推薦。特別是對於正在構建 AI Agent、遇到 Context Window 被垃圾對話塞滿、或是苦惱於 Agent 總是「忘記」關鍵細節的 AI 工程師與研究員。
第二部分:第二次閱讀精讀(30-60 分鐘精選)
目標:抓住方法、證據與對比,吃透技術細節。
1. 核心機制與推理鏈拆解
作者的推理鏈非常嚴密,從根本上否定了 RAG 在 Agent 場景的適用性:
- 前提:Agent 的記憶是同一個人在連續時間內的對話,具有極高的時間相關性與內容重複性。
- 推導 1:如果用向量相似度硬搜(Top-$k$),一定會搜出一堆背景相同但無助於回答問題的廢話(Collapsed Retrieval)。
- 推導 2:如果搜出來再用 LLMLingua 等工具壓縮(Pruning),因為對話中的代詞(他、那個)和時間線是交織的,壓縮會把推理的「橋樑」剪斷。
- 結論:必須在寫入時就進行解耦(Decoupling),在檢索時進行聚合(Aggregation)。
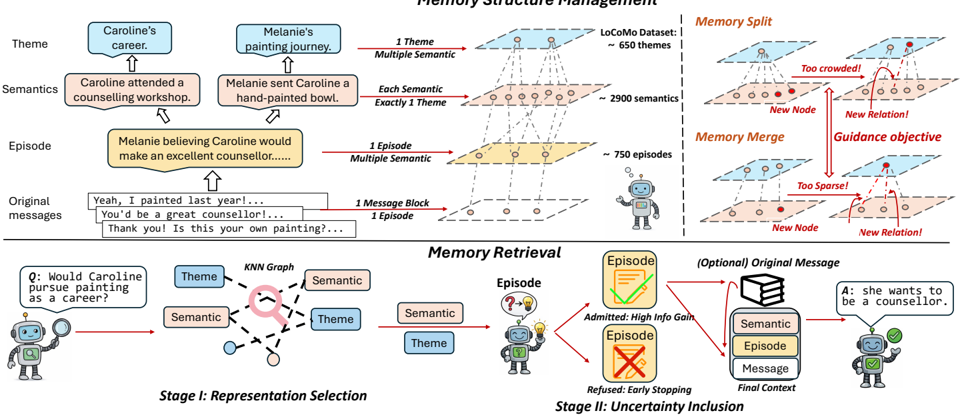 圖表解析:Figure 2 展示了 xMemory 的完整生命週期。
圖表解析:Figure 2 展示了 xMemory 的完整生命週期。
- 上半部(Memory Structure Management):展示了四層映射關係。原始訊息被打包成 Episode(情節);從 Episode 中提煉出 Semantic(語意,即長期事實);Semantic 再被歸類到 Theme(主題)。右側的 Guidance Objective 確保了 Theme 不會過度擁擠(觸發 Split)或過度稀疏(觸發 Merge)。
- 下半部(Memory Retrieval):
- Stage I(Representation Selection):在 Theme 和 Semantic 構成的 kNN 圖譜上,根據 Query 挑選具備多樣性的代表節點。
- Stage II(Uncertainty Inclusion):拿著選好的 Semantic 去找對應的 Episode。LLM 會評估「加入這個 Episode 是否能降低我回答問題的不確定性?」如果可以(High Info Gain),則納入 Context;如果不行,則觸發 Early Stopping 拒絕納入,從而嚴格控制 Token 數量。
2. 演算法與數學邏輯
論文中最精彩的數學設計在於記憶結構管理的引導函數(Guidance Objective)。為了解決主題(Theme)過大導致檢索退化,或過小導致語意破碎,作者設計了評分函數 $f(P)$ 來決定何時該 Split 或 Merge:
$f(P) = \text{SparsityScore}(P) + \text{SemanticScore}(P)$
-
SparsityScore(稀疏性得分): 目標是讓各個 Theme 的大小盡可能平均。作者利用資訊理論中的 Fano 不等式推導出,當候選集合過大時,誤判率必然上升。因此定義: $\text{SparsityScore}(P) = \frac{N}{2K} \sum_{k=1}^K (\frac{n_k}{N})^2$ 這個公式本質上是在懲罰過度臃腫的 Theme,鼓勵將大 Theme 拆分,以降低檢索時的掃描成本。
-
SemanticScore(語意得分): 包含群內凝聚力(Intra-theme)與群間排斥力(Inter-theme)。 $\text{SemanticScore}(P) = \frac{1}{N} \sum_{k=1}^K \sum_{i \in C_k} \cos(x_i, \mu_k) - \frac{1}{K} \sum_{k=1}^K \exp(-\frac{(s_k - m)^2}{2\sigma^2})$ 前半段確保同一個 Theme 內的 Semantic 向量 $x_i$ 靠近中心點 $\mu_k$。後半段是一個鐘型懲罰項,確保 Theme 之間不能太相似(會導致冗餘),也不能太疏遠(會變成「語意孤島」影響多跳推理)。
3. 圖表深度解析與概念驗證
A. 消融實驗與 Token 效率
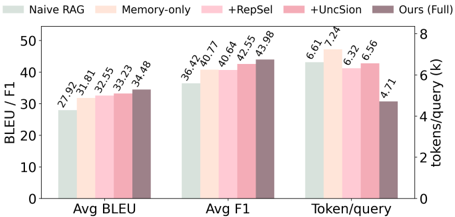 圖表解析:Figure 3 證明了雙階段檢索的必要性。
圖表解析:Figure 3 證明了雙階段檢索的必要性。
Memory-only(僅用階層結構但不用自適應檢索)雖然提升了 F1,但 Token 消耗極高(7.24k)。- 加入
+RepSel(第一階段:代表性選擇)後,Token 降至 6.32k,因為避免了在單一密集區域過度採樣。 - 加入
+UncSion(第二階段:不確定性包含)後,F1 提升至 42.55。 - Ours (Full) 結合兩者,達到了最高的 F1 (43.98) 與最低的 Token 消耗 (4.71k)。這證明了「精準挑選 + 按需展開」是 Agent 記憶檢索的最佳解。
B. 證據密度分析(為什麼 Pruning 會失敗?)
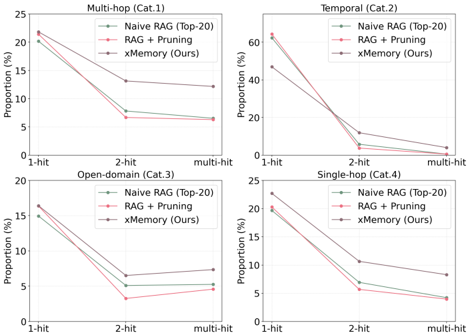 圖表解析:Figure 4 解釋了傳統 RAG 與剪枝技術的致命傷。
圖表統計了檢索到的文本塊中包含答案關鍵字的密度(1-hit, 2-hit, multi-hit)。
圖表解析:Figure 4 解釋了傳統 RAG 與剪枝技術的致命傷。
圖表統計了檢索到的文本塊中包含答案關鍵字的密度(1-hit, 2-hit, multi-hit)。
- 綠線(Naive RAG)和紅線(RAG + Pruning)在 2-hit 和 multi-hit 的比例顯著低於棕線(xMemory)。
- 特別是 RAG + Pruning,它把大量的質量轉移到了 1-hit。這證明了傳統的 Prompt 壓縮技術會把包含豐富細節的長邏輯鏈剪碎,導致 LLM 拿到的是缺乏上下文的孤立單詞,而 xMemory 透過保留完整的 Episode/Semantic 單元,提供了高密度的證據。
C. 記憶結構的動態可塑性
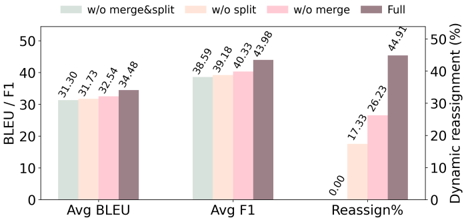 圖表解析:Figure 5 探討了「追溯重構(Retroactive Restructuring)」的價值。
Agent 的記憶是隨時間演進的。如果關閉 Split 和 Merge(
圖表解析:Figure 5 探討了「追溯重構(Retroactive Restructuring)」的價值。
Agent 的記憶是隨時間演進的。如果關閉 Split 和 Merge(w/o merge&split),動態重分配率為 0%,F1 僅有 38.59。當開啟完整的動態調整機制(Full)時,有高達 44.91% 的語意節點會在後續對話中被重新分配到更適合的主題中,這使得 F1 大幅提升至 43.98。這證明了記憶系統必須具備自我整理與演化的能力。
4. 嚴格審視與邊界測試
- 潛在風險與局限性:
- 寫入延遲與成本(Write Overhead):xMemory 在寫入階段需要呼叫 LLM 進行 Episode 總結與 Semantic 提取,這比單純的 Vector DB 寫入成本高得多。對於極高頻的即時對話,可能需要非同步處理(Asynchronous processing)來避免阻塞。
- 矛盾記憶的處理:論文提到在 Prompt 中指示 LLM「優先採信最新時間戳的記憶」。但如果語意層面(Semantic)提取了兩個截然相反的事實,Guidance Objective 是否會將它們分到同一個 Theme?檢索時 LLM 是否能穩定判斷?這在極端對抗測試中可能成為 Failure Case。
- 依賴底層 LLM 的能力:Stage II 的「不確定性評估」高度依賴 Reader LLM 的 logits 或自我評估能力(論文中 GPT-5-nano 甚至需要用 GPT-4.1-mini 來輔助計算 entropy)。如果使用較弱的開源小模型,這一步可能會失效,導致提早停止(漏掉資訊)或無限展開(Token 爆炸)。
5. 💡 總結與工程洞察
給開發者與研究者的具體建議:
- 拋棄「對話紀錄直入 Vector DB」的幻想:對於 Agent 應用,原始對話紀錄的價值極低且充滿雜訊。必須建立非同步的「記憶整理機制」(如本文的 Message $\rightarrow$ Episode $\rightarrow$ Semantic)。
- 剪枝(Pruning)的層級決定了成敗:不要在 Token 或字元級別進行剪枝(如 LLMLingua),這會破壞對話的指代關係。應該在「語意單元(Semantic Unit)」級別進行過濾,一旦決定納入某個證據,就應該給予完整的 Episode 上下文。
- 用算力換算力(ROI 極高):雖然 xMemory 在「記憶建構」時花費了額外的 LLM Token,但它在「每次檢索與回答」時省下了 30%-40% 的長文本 Token。考慮到 Agent 的生命週期中,讀取(檢索)的頻率遠大於寫入(總結),這種架構在工程實踐中不僅效果更好,長期營運成本也更低。
原始出處
- 論文:Beyond RAG for Agent Memory: Retrieval by Decoupling and Aggregation(arXiv,2026)