Google 發布 Agentic Resource Discovery 規範:AI Agent 時代的「能力黃頁」
標準化 Agent 的能力發現、身份驗證與安全連線,打造可信任的多 Agent 生態系

在 AI Agent 從實驗室走向生產環境的今天,一個迫切的工程問題浮上了水面:當一個 Agent 需要呼叫另一個 Agent,或使用某個外部工具時,它要如何知道對方在哪裡、對方是否可信、又該如何安全地建立連線?
這個問題,正是 Google 於 2026 年 6 月 17 日所公布的開放規範 Agentic Resource Discovery(ARD,智能體資源發現規範) 試圖根本性地解決的問題。
這份由 Google 資深工程師 Junjie Bu 與 Srinivas Krishnan 主導的規範,並非 Google 的私有協議,而是一份在 Apache 2.0 授權下開源、並公開邀請產業夥伴共同貢獻的開放標準。它的出現,標誌著 Agentic AI 基礎設施建設正式進入標準化階段。
§1 問題的根源:分散式 Agent 生態的「發現困境」
現況:工具多,但找不到、信不過
想像一個企業場景:一家大型金融機構正在部署多個 AI Agent,分別負責客戶服務、風險評估、法規合規與市場分析。這些 Agent 各自具備不同的能力,並且未來還會持續擴增。
當「客服 Agent」需要進行「法規查詢」時,它面臨三個核心問題:
- 能力位置 (Capability Location):哪裡有提供這個能力的 Agent 或工具?
- 選擇依據 (Selection Criteria):在多個候選者中,應該選哪一個?依據是什麼?
- 安全驗證 (Safety Verification):我如何確認對方的身份?如何防範假冒的惡意工具?
在 ARD 問世之前,這三個問題的答案大多是「寫死在程式碼裡」或「靠開發者人工維護」。這既脆弱、又無法規模化。
ARD 的定位
ARD 並非要取代 MCP(Model Context Protocol) 或 A2A(Agent-to-Agent Protocol) 等現有協議。這些協議解決的是「通訊的格式與語言」問題——兩個 Agent 說好之後,要怎麼交換訊息。
ARD 解決的則是更前置的問題:「要怎麼找到可以交談的對象?」 這是一套能力發現(Capability Discovery) 的基礎設施標準,讓 MCP 和 A2A 等協議有了可以運作的生態土壤。
§2 ARD 的核心架構:兩個關鍵角色
ARD 的設計圍繞著兩個主要概念構建:目錄(Catalogs) 與 登錄檔(Registries)。
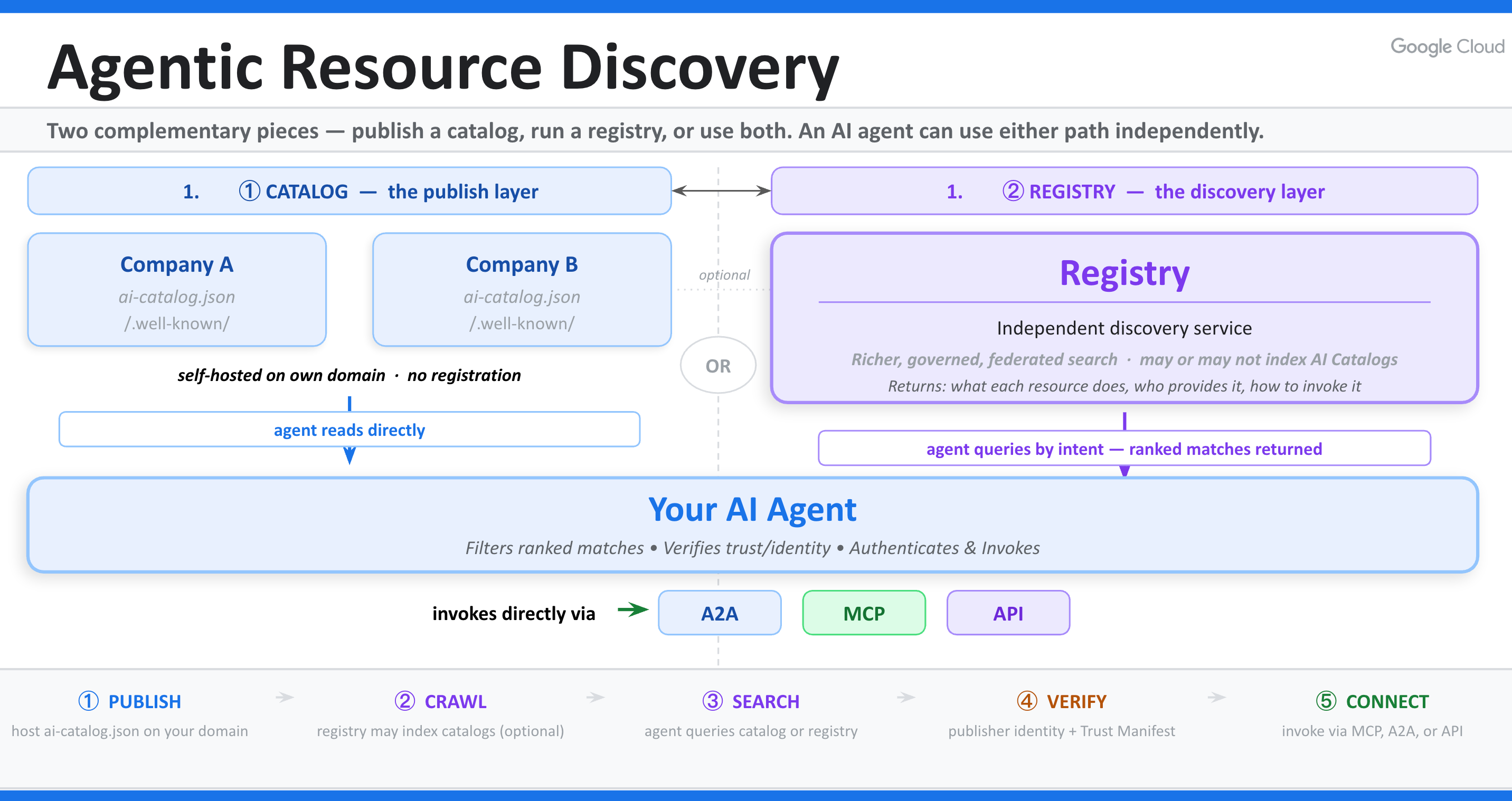 ARD 架構圖:左側組織在自有網域發佈
ARD 架構圖:左側組織在自有網域發佈 ai-catalog.json,Registry 爬取並建立索引,右側 Agent 透過 Registry 查詢後直接與目標服務建立連線。
Catalogs:能力的自我聲明
每個組織(或個人開發者)可以在其網域下,於標準路徑發佈一個 ai-catalog.json 檔案,聲明自己所提供的 AI 能力。
這個設計有一個精妙之處:它以網域所有權作為信任基礎。
就像你可以信任 google.com/.well-known/ai-catalog.json 是 Google 發佈的,而非冒牌貨,因為只有真正擁有該網域的人才能在 .well-known/ 路徑下放置檔案。這就是一種天然的密碼學信任錨點(Cryptographic Trust Anchor),無需額外的中央認證機構即可建立初始信任。
一個典型的 ai-catalog.json 可能包含:
- 該組織提供哪些 Agent 或工具
- 每個能力的功能描述、適用場景
- 連線所需的協議類型(如 MCP、A2A、REST)
- 安全驗證所需的密鑰或憑證資訊
Registries:能力的搜尋引擎
如果 Catalog 是各家發佈的「能力廣告」,那麼 Registry 就是「搜尋引擎」——它持續爬取各組織發佈的 Catalog,建立索引,並在 Agent 有查詢需求時,返回符合條件的資源列表與驗證元數據。
Registry 的角色類似於 DNS(域名系統),但服務的對象是 Agent 的能力,而非網址解析。它讓 Agent 可以用自然語言或結構化查詢去找到「世界上有哪些工具可以幫我做 X」。
§3 四個運作階段:從發現到連線
ARD 規範將 Agent 的能力發現流程標準化為四個階段,形成完整的閉環:
階段一:目錄發佈(Catalog Publication)
工具或 Agent 的提供者,在其網域的標準路徑下(.well-known/ai-catalog.json)發佈能力描述。這個步驟由人工完成,一次設定後持續有效。
階段二:能力發現(Capability Discovery)
消費端的 Agent 有兩種方式尋找能力:
- 直接抓取:若已知對方網域,直接 fetch 其 Catalog 檔案。
- 透過 Registry 查詢:向 Registry 發出查詢請求,由 Registry 返回符合條件的結果。
階段三:密碼學驗證(Cryptographic Verification)
找到候選能力後,Agent 必須驗證其真實性。ARD 採用密碼學簽章機制,確保「宣稱自己是 X 組織的 Agent」真的是 X 組織的 Agent,而不是假冒者。這是整個信任模型的關鍵防線。
階段四:執行期連線(Runtime Connection)
驗證通過後,雙方依照 Catalog 中聲明的原生協議(MCP、A2A、REST 等)建立連線,開始正式的任務協作。
§4 企業級整合:Google Cloud 的 Agent Registry
對於大型企業而言,自行維護 Catalog 與管理 Registry 仍然存在相當的操作複雜性。為此,Google Cloud 在其 Gemini 企業 Agent 平台(Gemini Enterprise Agent Platform) 中推出了 Agent Registry 服務,作為 ARD 規範的託管實作。
Agent Registry 提供的企業級能力包括:
| 功能 | 說明 |
|---|---|
| 託管式發現(Hosted Discovery) | 無需自行架設 Registry,由 Google Cloud 管理 |
| 資源治理(Resource Governance) | 集中管控哪些 Agent 可以被發現、被誰使用 |
| 全球唯一命名空間(Globally Unique Namespace) | 避免不同組織的 Agent 名稱衝突 |
| 出口政策執行(Egress Policy Enforcement) | 控制 Agent 可以對外連接哪些資源 |
| 合規支援(Compliance Support) | 透過密碼學信任清單(Cryptographic Trust Manifests)支援法規要求 |
這讓 ARD 不只是一份紙上的標準,而是擁有可立即落地的雲端基礎設施。
§5 為什麼這件事很重要?
從「API 整合」到「生態系發現」
過去,軟體整合的方式是「人找人」:開發者閱讀文件、手動設定 API 金鑰、撰寫整合程式碼。這個流程以人為中心,速度慢且難以規模化。
ARD 的願景是讓這個過程由 Agent 自動完成:一個 Agent 在執行任務時,可以動態地發現它需要的能力,自動驗證對方的身份,並自動建立連線——整個過程無需人工介入。
這是 Agentic AI 從「工具」升格為「生態系」的必要基礎設施。
開放標準的意義
ARD 選擇以開放標準的形式推出,而非 Google 的私有協議,這具有深遠的戰略意義:
- 降低採用門檻:任何組織都可以無障礙地實作 ARD,無需付費或授權。
- 建立互操作性:不同廠商的 Agent 平台,只要都遵循 ARD 規範,就能互相發現和協作。
- 防止生態碎片化:避免重蹈 AI 工具層各自為政、形成孤島的問題。
![]() ARD 規範由 Google 主導,並與眾多產業夥伴共同開發,展現出跨廠商的生態系凝聚力。
ARD 規範由 Google 主導,並與眾多產業夥伴共同開發,展現出跨廠商的生態系凝聚力。
類比歷史上的先例:SMTP 讓不同電子郵件服務商可以互通;HTTP 讓不同的網頁伺服器可以被任何瀏覽器存取。ARD 的野心,是成為 Agentic AI 世界的底層連結協議。
與 MCP 和 A2A 的互補關係
這三個規範共同構成了多 Agent 系統的基礎設施堆疊:
┌─────────────────────────────────────────────┐
│ 應用層:任務執行 / 業務邏輯 │
├─────────────────────────────────────────────┤
│ 協議層:MCP(工具呼叫)/ A2A(Agent 通訊)│
├─────────────────────────────────────────────┤
│ 發現層:ARD(能力發現 / 身份驗證) │ ← 本文重點
├─────────────────────────────────────────────┤
│ 基礎層:DNS / HTTPS / 網域所有權 │
└─────────────────────────────────────────────┘三者缺一不可:有了 ARD,Agent 才知道去哪裡;有了 MCP/A2A,Agent 才知道怎麼說話;有了業務邏輯,Agent 才知道要做什麼。
§6 如何開始?
Google 為開發者提供了三個入門路徑:
-
閱讀規範文件:ARD 的完整技術規範已發布於官方文件網站,涵蓋 Catalog Schema、Registry API 定義與密碼學驗證細節。
-
跟隨 Quickstart 指南:適合想快速上手的開發者,引導完成從發佈第一個
ai-catalog.json到透過 Registry 被發現的完整流程。 -
參與開源社群:ARD 的規範與參考實作托管於 GitHub,採用 Apache 2.0 授權,歡迎所有開發者提交 Issue 或 Pull Request。
小結:基礎設施時刻
ARD 的發布,標誌著 Agentic AI 進入了一個重要的成熟階段——基礎設施時刻(Infrastructure Moment)。
這個時刻在每一項變革性技術的發展歷程中都會出現。網際網路有了 HTTP 和 DNS 之後,才有了 WWW 的爆發;雲端計算有了 API 標準化之後,才有了 SaaS 的繁榮。
Agentic AI 正在迎接屬於自己的這個時刻。當 Agent 能夠可靠地找到、驗證、並連接世界上的任何能力,我們才能真正看到多 Agent 協作的全部潛力——那將是一個 AI 系統能夠自主組成臨時團隊、彼此分工合作、完成複雜任務的世界。
ARD 不只是一份技術規範,它是這個未來世界的第一塊基石。
原文出處: 本文深度解讀自 Google Developers Blog 官方發布文章:
- Announcing the Agentic Resource Discovery specification (2026/06/17)
- 作者:Junjie Bu (Senior Staff Software Engineer) 與 Srinivas Krishnan (Distinguished Software Engineer)