RAG without Forgetting:把 Query 擴展經驗寫進 Key 記憶
論文深度解析報告:RAG without Forgetting: Continual Query-Infused Key Memory
第一部分:第一次閱讀筆記(5-10 分鐘海選)
目標:鳥瞰論文,判斷價值。
1. 🧱 為什麼要讀這篇?解決什麼「坑」?(背景與動機)
在目前的 RAG(檢索增強生成)系統中,為了解決「使用者問題(Query)」與「文件庫(Document)」之間的語義代溝,業界常使用 Query Expansion (QE, 查詢擴展)(例如 HyDE,用 LLM 先生成假答案再檢索)。 坑在哪裡?
- QE 是「無狀態的」(Stateless): 每次使用者發問,系統都要重新呼叫 LLM 做擴展,算完、檢索完就丟掉。這導致推論成本極高、延遲極大,且系統無法從過去成功的檢索經驗中「累積學習」。
- Key Expansion (KE, 索引擴展) 不接地氣: 另一派做法是離線把文件擴寫(例如幫文件總結摘要再存入向量庫),但這與實際使用者的 Query 分佈脫節,容易產生語義偏移(Semantic Drift)和雜訊。
2. 🛠️ 技術定位:它到底「做了什麼」?(核心貢獻與方法簡述)
這篇論文提出了一個名為 ERM (Evolving Retrieval Memory, 演化檢索記憶) 的免訓練 (Training-free) 框架。 它的核心思想是:「把線上短暫的 Query 擴展紅利,白嫖下來變成離線持久的 Key(文件索引)升級。」 當某個 Query 擴展成功幫助 RAG 找到正確答案後,ERM 會把這個擴展的特徵「刻」進對應文件的向量索引(Key)中。下次遇到類似問題,系統不需要再做昂貴的 Query 擴展,直接用原生的檢索速度就能精準命中。
3. 🔍 論文摘要精要
一句話總結: ERM 透過「正確性閘門」與「選擇性歸因」,將高成本的線上查詢擴展(Query Expansion)轉化為穩定、持久的文件索引(Key)更新,實現了零推論延遲的持續學習 RAG 系統。
4. 📊 第一遍必看圖表解析:系統架構與核心對比
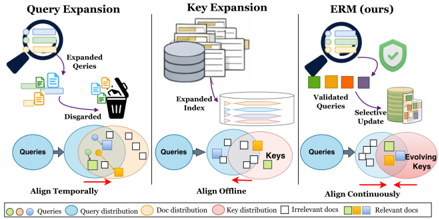 圖表解析:
圖表解析:
- 左圖 (Query Expansion): 臨時抱佛腳。每次 Query 來了才擴展,檢索完就丟進垃圾桶(Discarded),無法累積。
- 中圖 (Key Expansion): 閉門造車。離線擴展文件庫,但跟真實 Query 沒對齊,導致 Key 的分佈與 Query 分佈有落差。
- 右圖 (ERM - 本文方法): 持續對齊。將被驗證過有效的 Query 擴展特徵(Validated Queries),選擇性地更新到對應的文件 Key 上(Evolving Keys),讓文件庫的向量分佈主動「走向」真實使用者的發問分佈。
5. 💡 工程直覺:這東西離落地有多遠?(初步評估)
非常近,甚至可以直接寫進現有的 RAG 基礎設施中。
- 免訓練: 不需要重新 fine-tune 任何 Embedding 模型。
- 零推論延遲: 所有的「進化」都發生在背景(非同步更新 Key),線上推論時就是最單純的向量內積(Dot Product),速度極快。
- 極度適合企業級 QA: 企業內部的問題通常符合長尾分佈(Zipf-like),高頻問題反覆出現。ERM 可以讓系統「越用越聰明」。
6. 🏁 第一遍速讀結論:三個關鍵判斷
- 解什麼: RAG 系統無法記憶成功經驗(Stateless)以及 LLM 查詢擴展帶來的巨大推論延遲。
- 憑什麼: 理論證明了 Query 擴展與 Key 擴展在數學上是等價的;並設計了嚴格的驗證機制確保索引更新不會崩壞。
- 值得深讀嗎: 🌟🌟🌟🌟🌟 (滿分)。對於致力於優化 RAG 檢索效能、降低 API 成本的 AI 工程師與研究員來說,這是一篇必讀的架構級論文。
第二部分:第二次閱讀精讀(30-60 分鐘精選)
目標:抓住方法、證據與對比,吃透技術細節。
1. 核心機制:深入拆解 ERM 底層邏輯
ERM 的運作流程非常嚴謹,為了防止把「垃圾」寫進文件索引庫,它設計了三個關鍵步驟:
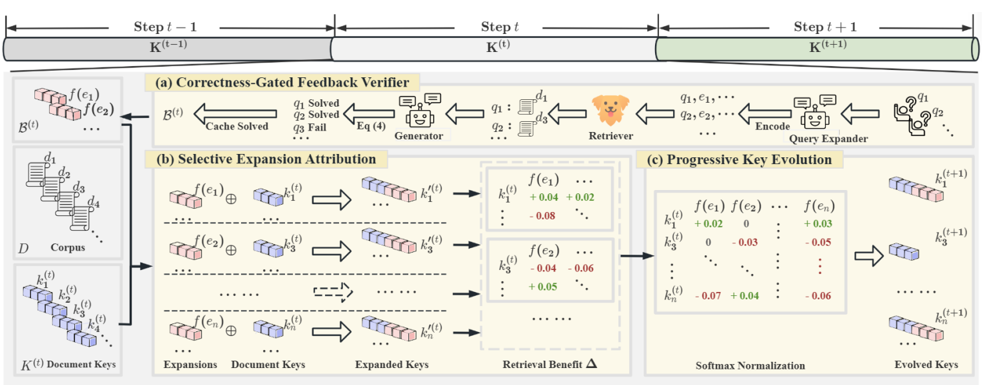 圖表解析(對應圖中 a, b, c 三階段):
圖表解析(對應圖中 a, b, c 三階段):
- (a) Correctness-Gated Feedback Verifier (正確性閘門驗證): 不是所有的 Query 擴展都有用。ERM 會看這個擴展是否真的提升了檢索指標(如 Recall)或生成指標(如 ROUGE 或 LLM-as-judge)。只有「被驗證能解決任務」的擴展單元(Expansion units)才會被放行進入快取。
- (b) Selective Expansion Attribution (選擇性擴展歸因): 一個 Query 可能擴展出多個詞/特徵,但不是每個特徵都對所有檢索到的文件有幫助。ERM 會計算邊際效益(Marginal Benefit, $\Delta$)。只有當某個擴展特徵能讓該文件與原 Query 的相似度提升($\Delta > 0$)時,這個特徵才會被分配給該文件。
- (c) Progressive Key Evolution (漸進式 Key 演化): 為了防止索引崩壞,ERM 不會無腦疊加向量。它會對累積的特徵進行 Softmax 正規化,並只挑選分數最高的前 $x$ 個特徵(Top-x selection)來與原文件的 Key 進行向量相加(Additive composition)。
2. 檢索/運算演算法:數學基礎與理論保證
論文提出了幾個非常漂亮的數學證明來支撐其工程設計:
- Proposition 4.1 (Query-Key 等價性): 在標準的內積(Inner-product)或加法嵌入空間中,擴展 Query 等同於擴展 Key。 公式:$sim(q \oplus f(e), k) = sim(q, k \oplus f(e))$ 這意味著我們完全可以把原本要在 Query 端做的事情,轉移到 Key 端預先做好。
- Theorem 4.3 (穩定性與收斂保證): 只要擴展向量的範數(Norm)是有界的,ERM 的漸進式更新就保證會收斂到一個穩定的索引狀態,不會因為不斷更新而導致向量空間爆炸或發散。
3. 實戰表現與數據分析
論文在 BEIR 和 BRIGHT 共 13 個資料集上進行了測試,結果極具說服力。
A. 效能與延遲的完美權衡 (Latency vs. Performance)
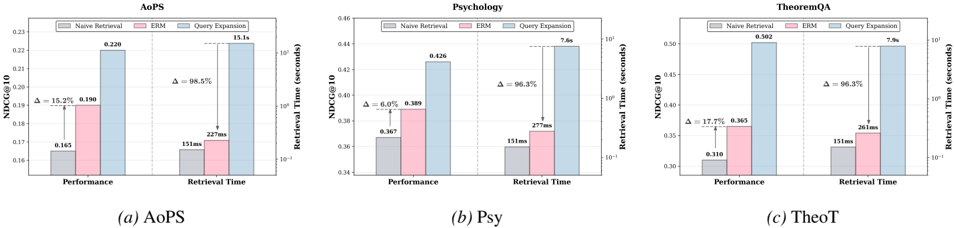 圖表解析:
圖表解析:
- 藍條 (Query Expansion, HyDE): 效能好,但延遲極高(需要 7~15 秒,因為要等 LLM 生成)。
- 灰條 (Naive Retrieval): 速度快(150ms),但效能差。
- 粉紅條 (ERM, 本文方法): 效能追平甚至超越 HyDE,但延遲與 Naive Retrieval 一樣快(毫秒級)! 這是因為 ERM 把 HyDE 的智慧已經提前寫進 Key 裡了。
B. 對各種擴展方法的泛化能力
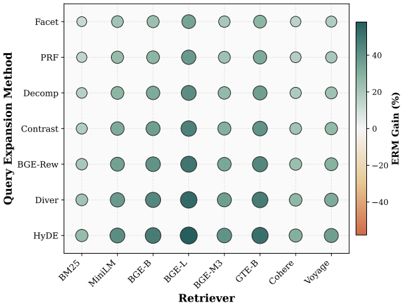 圖表解析:
這張泡泡圖展示了在 LeetCode 資料集上,ERM 搭配各種檢索器(X軸)與各種 Query 擴展方法(Y軸)的表現。全部都是綠色(正增益)!
圖表解析:
這張泡泡圖展示了在 LeetCode 資料集上,ERM 搭配各種檢索器(X軸)與各種 Query 擴展方法(Y軸)的表現。全部都是綠色(正增益)!
- 無論是搭配傳統的 BM25,還是強大的 BGE-Large、Cohere、Voyage 等商業模型,ERM 都能帶來穩定提升。
- 特別是在需要複雜推理的任務(如數學 AoPS、程式碼 LeetCode)上,提升幅度高達 40%~2200% 不等。
4. 嚴格審視:潛在風險與局限性 (Failure Cases)
儘管 ERM 設計精良,但從工程落地的角度來看,仍有幾個需要注意的局限性:
- 冷啟動問題 (Cold Start): ERM 依賴「過去成功的 Query」。如果系統剛上線,沒有累積足夠的歷史 Query,ERM 就無法發揮作用。初期仍需依賴高成本的線上 Query Expansion。
- 馬太效應與早期偏誤 (Early Bias): 由於 ERM 會強化「已經被成功檢索到的文件」,這可能導致強者恆強。如果早期系統因為偏誤檢索到了次佳文件並強化了它,可能會導致真正最好的文件永遠無法出頭(論文建議透過增加 Batch size 和耐心停止條件來緩解)。
- 記憶體與儲存開銷: 雖然推論時沒有額外延遲,但在背景維護每個文件的「擴展記憶緩衝區(Expansion memory $u_i$)」需要額外的儲存空間與運算資源。
5. 💡 總結與工程洞察:給開發者或研究者的具體建議
這篇論文為 RAG 系統的架構設計帶來了極具價值的啟發:
- 架構建議:非同步的「慢思考」與「快直覺」分離。
在實務上,我們可以設計一套雙軌系統:
- 線上推論 (Fast): 使用 ERM 演化後的 Key 進行極速向量檢索,不呼叫 LLM 做 Query 擴展。
- 離線/非同步演化 (Slow): 收集使用者的真實 Query,在離線狀態下用最昂貴、最強的 LLM(如 GPT-4o 做 HyDE 或分解)進行擴展,驗證後更新到向量資料庫中。
- 索引策略的改變: 論文實驗指出(附錄 B.8),「Title (標題) 索引 + ERM」 的效果往往比「全文索引」更好。這給我們的啟發是:與其把充滿雜訊的長文本全部塞進向量庫,不如一開始只 Embed 乾淨的標題或摘要,然後讓 ERM 根據真實使用者的發問,慢慢把有用的語義特徵「長」到這個乾淨的向量上。
最終評價: ERM 巧妙地解決了 RAG 系統中「算力浪費」與「無法持續學習」的痛點,是一套極具工程美感且隨插即用的優雅方案。
原始出處
- 論文:Hu, Li, Ramakrishnan, Zhao. RAG without Forgetting: Continual Query-Infused Key Memory. arXiv:2602.05152(2026)