Harness Engineering:讓 Codex 可觀測可交接
原文出處:
Ryan Lopopolo(2026). 運用工程技術:在智慧體優先的世界中善用 Codex.
網址:https://openai.com/zh-Hant/index/harness-engineering/
當工程從「人類撰寫程式碼」轉向「智慧體生成程式碼」時,最昂貴的資源不再是 API 次數,而是人類的時間與注意力。OpenAI 在這篇工程文章中,用一個幾乎沒有手動程式碼的內部產品實驗,說明了智慧體要能穩定交付,必須把「工程環境」做成可讀、可驗證、可強制執行的 harness。
這篇文章的價值在於:它不是把成功歸因於更強的模型,而是把問題落到可操作的工程建設上——從知識地圖(docs/ 與 AGENTS.md 角色)、到端到端可重現(UI、日誌、指標)、再到分層架構邊界(cross-cutting concern 透過單一介面進入)。
當程式碼由智慧體生成時,Harness 的核心工作是:把「回饋迴路、架構邊界與觀測性」工程化,讓錯誤能被偵測、修正能被接續,而不是靠提示詞期望模型自覺。
背景:工程師角色改寫成「建環境與回饋迴路」
OpenAI 描述他們的團隊在五個月內交付一款內部 Beta 產品,且「人類從未直接撰寫任何程式碼」。所有應用程式邏輯、測試、CI 設定、文件、可觀測性以及內部工具,皆由 Codex 撰寫。他們估計整體工作量只需要手動寫程式碼的約 1/10 時間。
在投入的人力規模上,推動 Codex 的小型團隊僅有 三位工程師,程式碼庫最終累積約 一百萬行程式碼,並在期間開啟並合併約 1,500 個 pull request;當團隊成長到七位工程師後,吞吐量反而仍在增加。
OpenAI 也指出進展變慢的原因,常不是 Codex 不夠,而是環境規格不夠明確:智慧體缺少完成任務所需的工具、抽象概念與內部結構。因此工程師的主要任務變成讓智慧體「看得懂、做得到、做完還能接著做」。
核心概念 1:用知識地圖替代「萬頁說明手冊」
長上下文固然重要,但 OpenAI 的早期教訓是:給智慧體一份龐大 AGENTS.md(或類似單一巨檔)往往會在幾個層面失敗:
- 背景資訊成為稀缺資源:巨大的指令檔會擠壓任務、程式碼與相關文件,導致智慧體漏掉關鍵限制或優化到錯的方向。
- 過多指導會變成非指導(non-instruction):當每件事都「很重要」,智慧體反而會在本地做模式匹配,而不是有意識導航。
- 文件會即時腐爛:一大本手冊難以驗證覆蓋性與新鮮度,最後變成陳舊規則的墳墓。
- 難以驗證:單一大雜燴不利於 coverage、freshness、ownership 與 cross-links 等機械檢查。
因此他們把 AGENTS.md 從百科全書轉成「目錄表」:程式碼庫知識庫位於結構化的 docs/ 目錄,AGENTS.md 只作為約 100 行的地圖,注入上下文的同時指向其他更真實的來源。
更進一步,知識庫的更新不是靠人盯:專用的 linter 與 CI 會驗證結構與交叉連結是否正確,並由定期執行的「doc-gardening」智慧體掃描過時或不再使用的文件,必要時直接開啟修正用 pull request。
核心概念 2:讓智慧體能「端到端驗證」而非只讀懂程式碼
隨著程式碼吞吐量增加,人力 QA 會成為瓶頸;OpenAI 的做法是讓 UI、日誌與應用程式指標等資訊可以直接被 Codex 理解,並能被智慧體重現與推理。
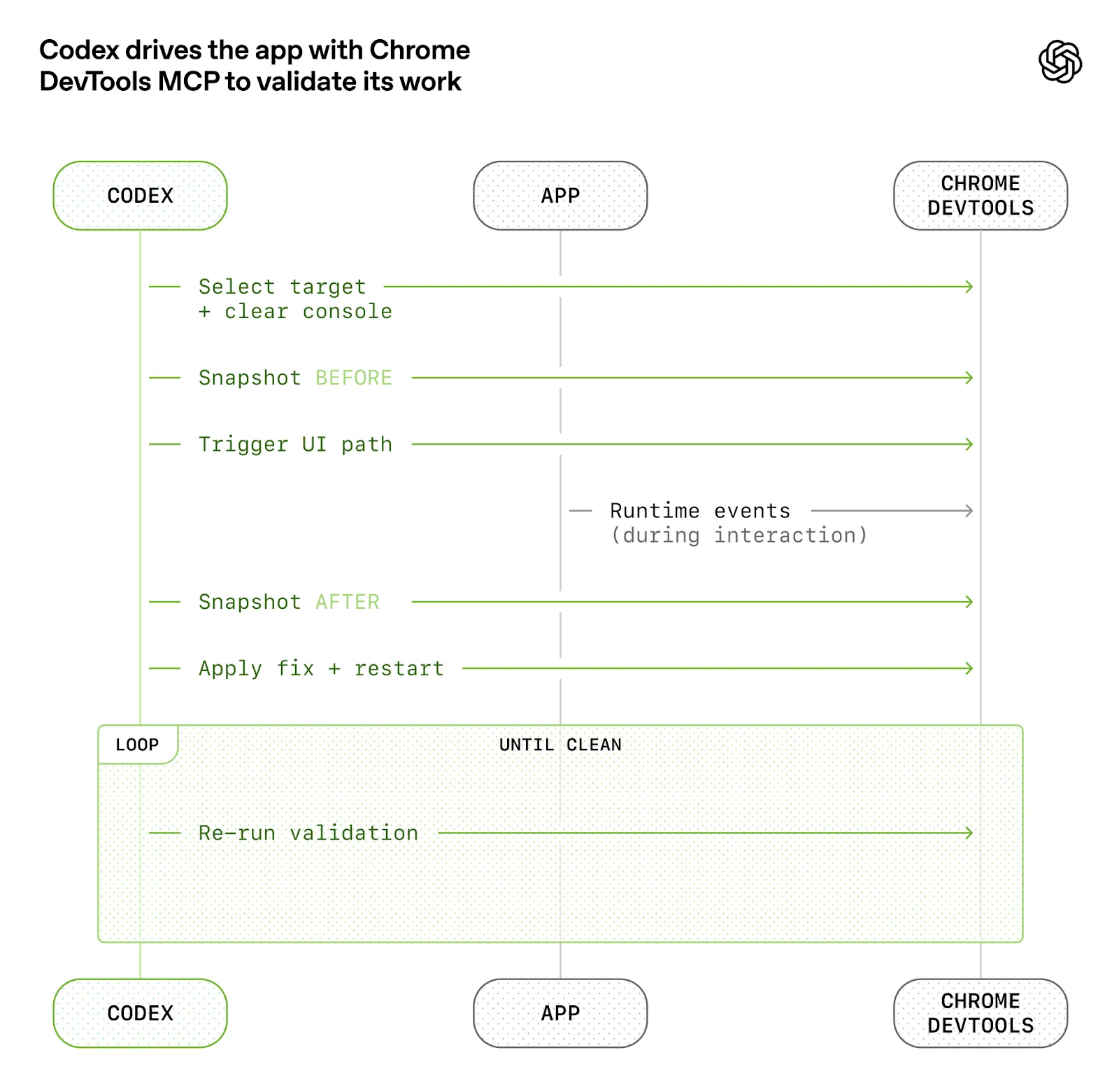
例如他們讓應用程式可以依 git worktree 啟動,使 Codex 能針對每次變更啟動隔離執行個體;同時把 Chrome DevTools 協定接入智慧體執行階段,並建立處理 DOM 快照、螢幕截圖與導航的技能,讓 Codex 能重現錯誤、驗證修正並推理 UI 行為。
在可觀測性方面,他們也採同樣原則:日誌、指標與追蹤資料以本地可觀測性堆疊暴露給 Codex,且代理在任務完成後會拆除相對應的隔離版本。這使得「確保服務在 800 毫秒內啟動」或「四個關鍵使用者旅程中的任何跨度都不超過兩秒」這類提示詞變得可行,因為智慧體有能查詢的工具(如 LogQL 與 PromQL)。
對外界而言,這種能力意味著 Codex 可以持續運行,並在通常是人類睡覺的時間內完成一次單一任務(常見超過六小時)。
核心概念 3:強制分層架構與邊界,讓「結構一致性」可被機械化
僅靠文件不足以維持完全由智慧體生成的程式碼庫一致性。OpenAI 選擇用「邊界不變量」取代事無巨細的實作管理:在邊界處解析資料形狀,但不限制模型採用哪個函式庫;在每個業務領域內限制依賴方向與允許的邊界集合;並透過自訂程式碼格式檢查器與結構測試機械地強制執行。
文章提到的例子,是使用分層架構模型(layered domain architecture),並把橫切關注點(如驗證、連接器、遙測、功能旗標)透過單一明確介面 Provider 進入;除此之外,其他事情一律不允許。分層順序大致為 Types → Config → Repo → Service → Runtime → UI,透過自動檢查器與結構測試讓此規則可被遵守。
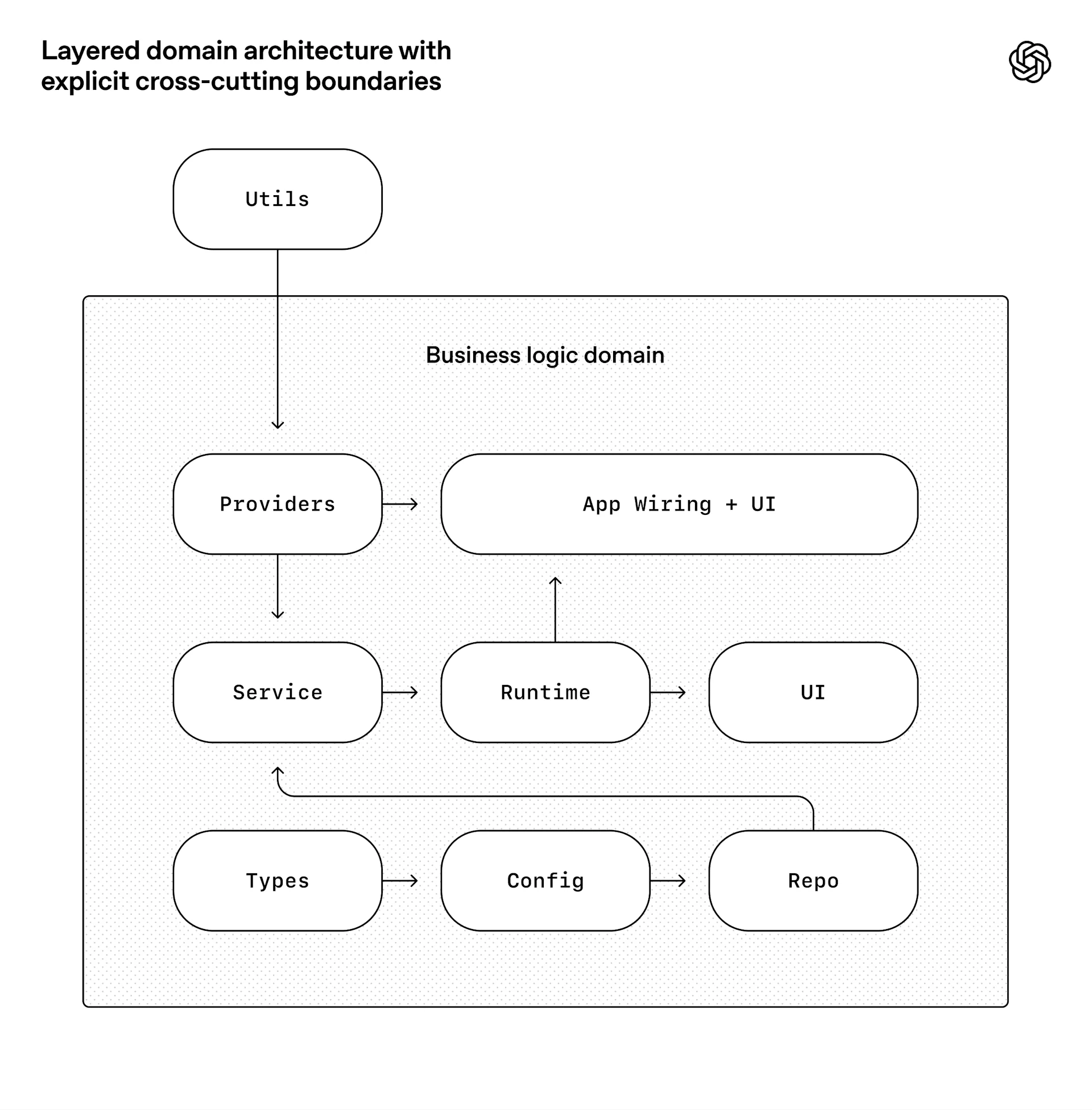
這樣的限制通常是大型團隊在數百工程師規模才會做的工程化工作;但對編碼代理而言,它反而是早期的先決條件:限制條件讓速度能在不衰退或架構漂移的情況下持續。
核心概念 4:接受智慧體「可存取知識」的上限,並把關鍵上下文內化到 repo
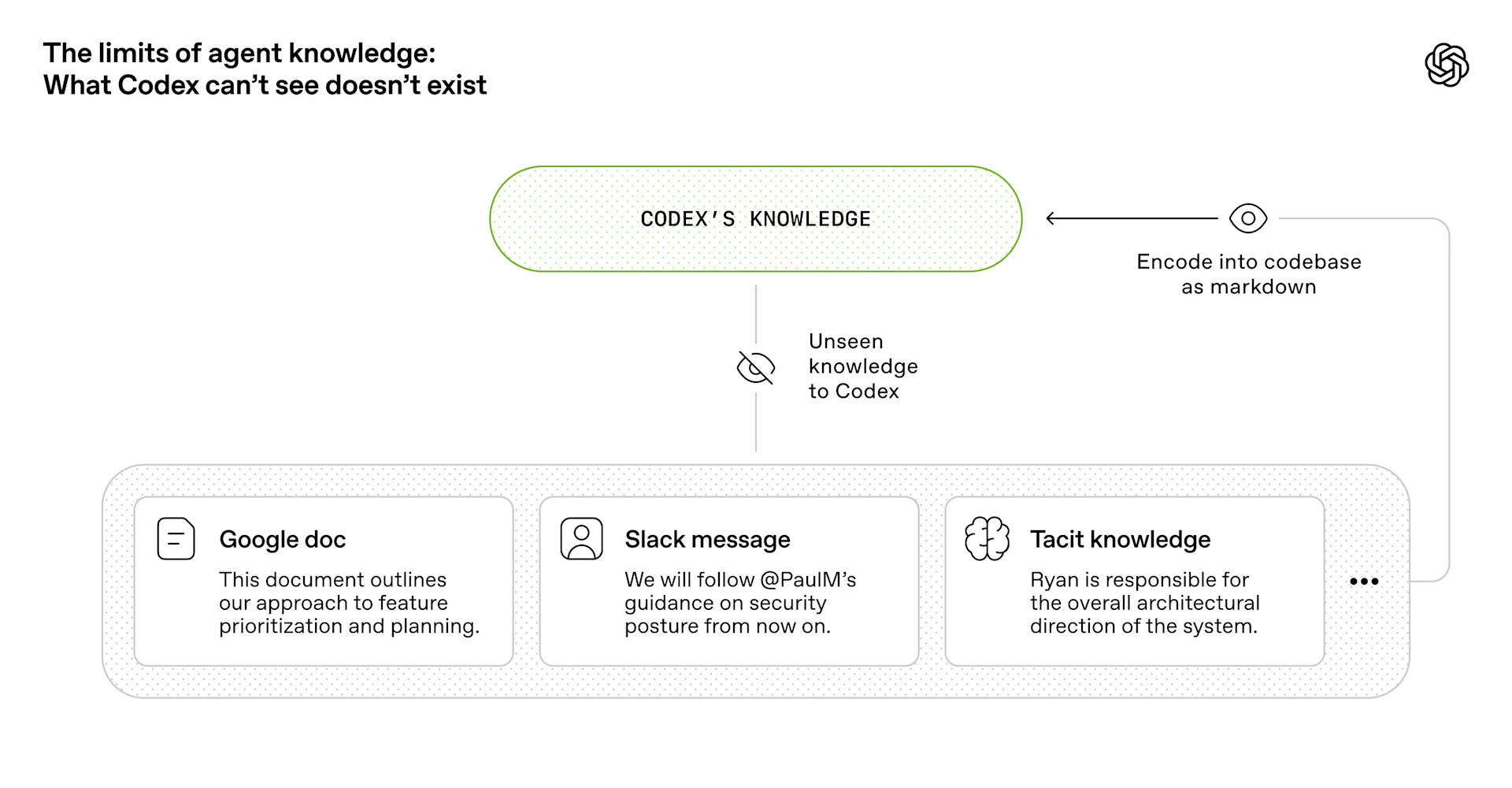
OpenAI 強調:對智慧體而言,任何它在執行時無法在上下文中存取的內容,實際上都不存在。因此「知識可用性」不是抽象問題,而是你要把上下文變成智慧體可看見、可推理、可驗證與可直接修改的 repo 工件。
他們指出,隨時間推移,會需要把越來越多上下文推送回儲存庫:例如 Slack 上團隊對齊架構模式的討論,如果智慧體找不到它,就如同三個月後的新進人員一樣難以辨識。
因此他們偏好把相依性與抽象概念內化到 repo 內,並透過版本化工件(程式碼、Markdown、結構描述、可執行計畫)讓智慧體能依據「它所能看到的全部」持續做出一致推論。
數據/觀察:吞吐量改變合併哲學與「垃圾回收」需求
在智慧體吞吐量遠高於人類注意力的系統中,OpenAI 認為許多傳統工程規範會失去效用。他們採用更少阻擋式的合併閘門(merge gates):pull request 生命週期更短,測試不穩定通常透過後續重跑處理,而不是無限期阻礙進度。
同時,完整智慧體自主性也帶來「AI 殘渣複製」問題:Codex 會複製程式碼庫中既有的模式,即使是彼此不一致或不理想的模式,久而久之會導致偏移。過去團隊原本每週五花時間清理 AI 殘渣,但並沒有很好地擴展。
於是他們把「黃金原則」制度化進程式碼庫,並建立固定循環的清理機制,主動掃描偏離、更新品質評級,並開啟具針對性的重構 pull request;多數變更可在一分鐘內審閱並自動合併。這件事在工程上類似垃圾回收:技術債高利率地累積,分段、持續地小額償還通常優於放任複利。
啟示與建議:打造「可長期維護」的 harness engineering
把這篇文章濃縮成可以落地的做法,我會給四個工程導向建議:
- 將規範從「提示詞」改為「可機械檢查」:用 linter、CI、結構測試把不變量寫進系統,而不是寫在文件角落。
- 把知識做成地圖而不是百科:用短小的目錄表 + 結構化 docs,並讓 doc-gardening 持續維護新鮮度與交叉連結。
- 讓回饋變成端到端驗證:把 UI、日誌與指標接到智慧體能查詢與能驅動的工具鏈,讓錯誤能被重現、修正能被操作驗證。
- 內化「智慧體可存取的世界」:你希望智慧體理解的內容,必須以 repo 工件形式存在;否則就算人類覺得「它應該知道」,智慧體也不會知道。
小結
OpenAI 的核心訊息是:當智慧體承擔更多程式生命週期工作後,工程紀律仍然存在,但它更像是一套框架與回饋迴路,而不是人手逐行修補程式碼。好的 harness engineering,讓錯誤能被觀測、讓修正能被接續、讓架構能在高吞吐下保持一致,最終把人類注意力留給真正稀缺的決策與取捨。
原文出處:
Ryan Lopopolo(2026). 運用工程技術:在智慧體優先的世界中善用 Codex.
網址:https://openai.com/zh-Hant/index/harness-engineering/